When a user asks something that requires recent information, an LLM does not answer only from its internal memory. It can activate search systems, retrieve web fragments, compare them semantically, validate sources and build an answer grounded in up-to-date information.
The technical question is: how does an LLM move from a user's prompt to an answer based on documents, search results and retrieved fragments in real time?
This article explains that flow. It helps explain why ChatGPT, Gemini, Claude, Copilot and Perplexity may answer the same question differently, why they do not value the same sources in the same way, and why optimization for LLMs is not about publishing more. It is about understanding which fragments the models retrieve, for what intent, and inside which context.
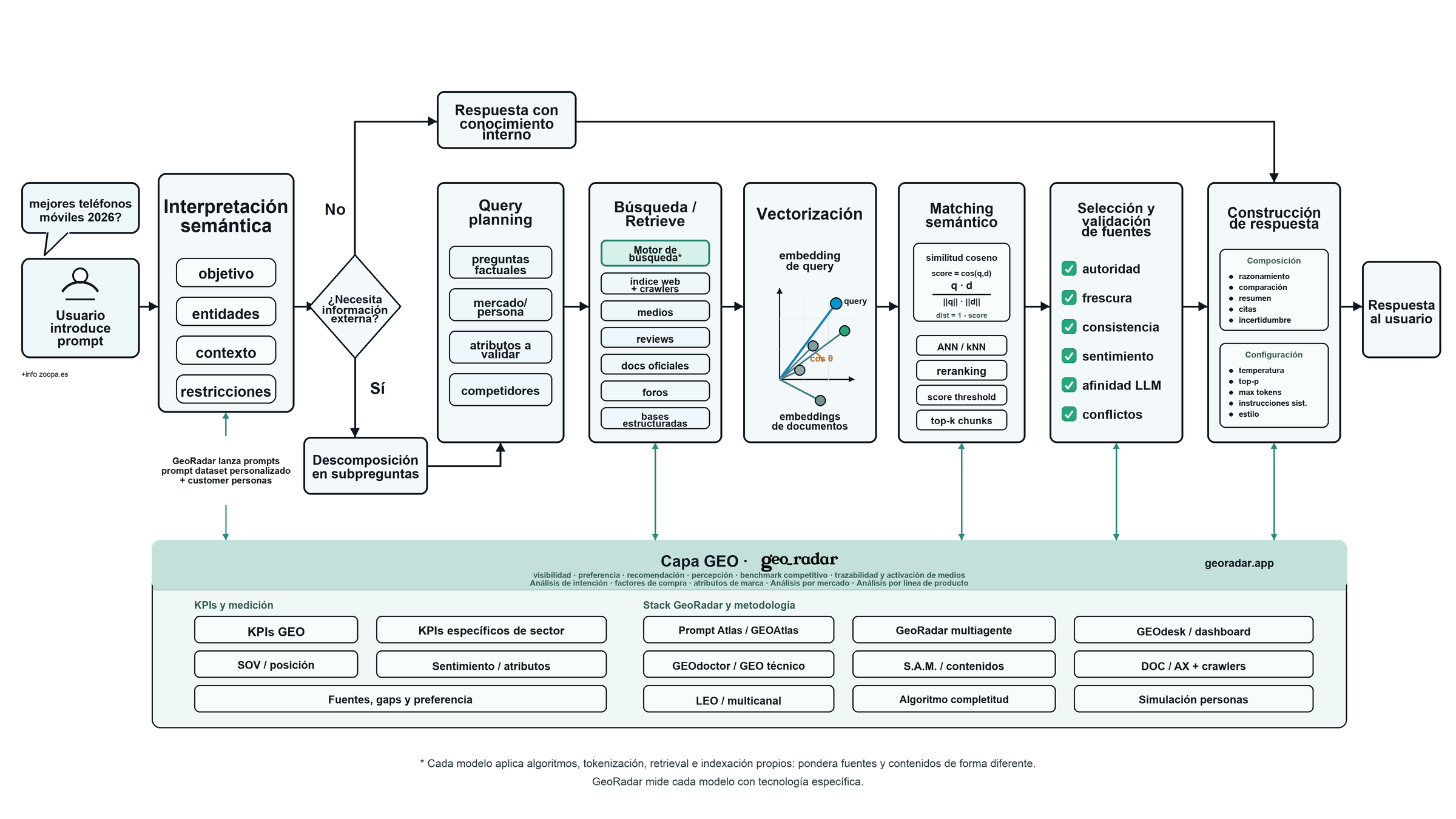
High-resolution diagram: prompt, query planning, retrieval, vectorization, semantic matching, source validation and answer construction.
Core idea
An LLM rarely answers a complex question in a single jump. First it does something close to clearing the table: it interprets what is being asked, detects entities, looks at conversational context and decides whether it can answer from what it already knows or whether it needs to search.
When it needs current data, another machine starts working: search, crawling, fragment retrieval, semantic comparison, source validation and, finally, response composition.
This is the important part for GEO. Many answers do not come only from the model's pre-trained knowledge. They come from a mix of reasoning, retrieval, discovered sources and internal composition criteria. OpenAI documents, for example, that ChatGPT Search can decide to search the web depending on the user's question, or allow the user to trigger search manually.
In any category where freshness, comparison or decision-making matters, this changes the rules. An answer about "best banks for young people", "phones with the best after-sales service" or "reliable fashion brands in Spain" may be shaped by fragments retrieved from media, official websites, comparisons, forums, technical documentation, marketplaces or user reviews.
What happens when the user asks
If someone writes best mobile phones 2026, the model is not reading only four words. It is reading a purchase intent. There is comparison, freshness, risk of obsolescence, candidate brands, possible price ranges and a fairly clear expectation: the user wants a recommendation, not a definition of what a phone is.
The system analyzes:
- response objective;
- mentioned or implicit entities;
- conversational context;
- market, language and date;
- explicit constraints;
- implicit value criteria;
- purchase factors;
- relevant brand attributes;
- required freshness level.
That nuance changes everything that follows.
Search decision
The model, or the orchestration layer around it, decides whether it can answer from internal knowledge or whether it needs external information. For current, comparative, transactional, reputational or market-specific questions, some form of retrieval is usually activated: web search, index lookup, connectors or structured sources.
The decision may depend on:
- freshness of the question;
- presence of dates such as
2026; - need for prices, availability or new information;
- risk of outdated information;
- need to compare brands;
- need to cite or validate sources;
- likelihood that the user expects recent data.
If search is activated, the original prompt becomes a set of subquestions.
Example:
- best smartphones 2026;
- phones with the best camera;
- iPhone Samsung Xiaomi comparison;
- user opinions about battery life;
- best phones to buy in Spain;
- frequent problems by model;
- most recommended brands by price segment.
In a reputational or commercial query, that decomposition may include searches such as:
- user ratings for a brand;
- frequent service complaints;
- average rating on review platforms;
- user experience in forums;
- comparisons with competitors;
- verified reviews on specialized platforms.
Search engines and grounding by model
There is a common misunderstanding: assuming that if an LLM uses Bing, Google Search or another retrieval system, then it behaves like that search engine. It does not.
The search engine may provide URLs, snippets, documents or passages. Then the model does something else: it reinterprets, compresses, compares, discards and turns all of that into a conversational answer.
That is why two systems can consult similar sources and still generate different answers.
ChatGPT
OpenAI documents that ChatGPT Search can use external search providers, including Bing, together with other partners and retrieved content. But ChatGPT is not Bing with a conversational interface on top.
Search finds candidates. ChatGPT decides what to consult, how to reformulate the question, which fragments to use, how to synthesize them and how to respond according to its instructions, conversational context and policies.
In real use, ChatGPT may:
- decide whether to search;
- generate one or more queries;
- retrieve web results;
- open or synthesize sources;
- combine passages;
- cite results when the product supports it;
- compose a conversational answer.
The result is not a Bing ranking pasted onto the screen. It is a generative answer conditioned by search.
Gemini
Google documents Grounding with Google Search for Gemini. This means Gemini can ground an answer with Google Search results. But it does not turn Gemini into classic Google Search either.
Google Search may act as retrieval infrastructure. Gemini still applies its own prompt interpretation, context system, grounding mechanisms, filters and final generation.
There is a trap here for SEO teams: a page can rank well in Google Search and still not be the fragment Gemini chooses for a generative answer. To enter the answer, the page must be retrievable, clear, structured and useful for that specific conversational objective.
Microsoft Copilot
Microsoft Copilot naturally relies on the Bing and Microsoft ecosystem. In enterprise environments it may combine the web, Microsoft Graph, corporate documents, connectors and the user's permissions.
Microsoft documents agents and grounding experiences with Bing Search, but the final result is not a SERP either. Copilot transforms the prompt into queries, retrieves information, applies corporate context when available and generates an answer.
For GEO this matters a lot. The same content can behave differently in Copilot if it is evaluated in open web mode, inside a corporate tenant, with Microsoft Graph available or with internal connectors active.
Claude
Anthropic documents web search capabilities for Claude, with current information retrieval and citations. Unlike ChatGPT/Bing or Gemini/Google Search, public sources do not let us reduce Claude to a single external search engine.
What we do know is enough to measure it separately: Claude has its own system for search, source selection, citations, document reasoning and response policies.
It is often especially sensitive to context quality, documentary clarity, source consistency and the way evidence is presented. In a GEO study, inferring Claude from ChatGPT or Gemini is a mistake.
Perplexity
Perplexity presents itself as an answer-first and search-native system. Its Sonar and Search API products work with web search, retrieval and citations. The experience is designed to answer with visible sources, although that does not mean it selects or weights the same sources as Google, Bing, ChatGPT or Gemini.
In Perplexity, a source gains value when it is direct, current, verifiable and citable. For GEO, that gives weight to clean, updated, well-titled pages with explicit information and little ambiguity.
What matters for GEO
Each model has a different architecture:
- different search engine or retrieval provider;
- different query generation;
- different tokenization system;
- different embedding model;
- different chunking policy;
- different context window;
- different reranking;
- different tolerance for contradictory sources;
- different citation behavior;
- different synthesis style;
- different safety and brand policies.
The operational takeaway is simple: asking one LLM once is not enough. A serious GEO audit measures each model, market and customer persona separately.
Search, crawling and retrieval
The system does not read the internet as a person would. It does not read it like Google Search does when it returns a SERP either. It queries search engines, proprietary indexes, crawlers, document stores, structured sources or specific connectors.
And each LLM solves this layer differently. ChatGPT, Gemini, Claude, Copilot and Perplexity do not index, retrieve or weight results in the same way.
The process usually has four parts:
-
Query planning
The prompt becomes several queries designed to solve different parts of the problem. -
Crawling or index lookup
Crawlers and engines retrieve candidate pages, documents, tables, reviews, FAQs, product sheets, media, forums, official documentation or structured data. -
Fragment extraction
The system does not mainly work with whole domains. It extracts pieces of content: titles, paragraphs, lists, tables, product blocks, review fragments, FAQ answers, schema markup, dates, authors, entities, language and localization signals. -
Chunking and normalization
Content is cleaned and split into chunks: manageable fragments that preserve meaning. A chunk can be a review paragraph, a pricing table, a technical specification, a comparison or a block of user opinions.
Tokenization: why each LLM represents information differently
Before vectorizing or generating an answer, the model splits text into internal units: tokens. Sometimes a token is a word. Sometimes it is half a word, a sign, a frequent sequence or a sublexical piece.
Here a less visible but very important difference appears: each model family tokenizes in its own way. OpenAI uses tokenizers such as those in the tiktoken family. Google provides token-counting tools for Gemini. Anthropic documents its own token counting for Claude. Each system has its own vocabulary, context limits and text-splitting behavior.
So the model does not exactly see "words". It sees token sequences.
Conceptual example:
best mobile phones 2026
One model may split it roughly as:
bestmobilephones2026
Another may split it more granularly:
bestphonesmobile2026
Another may treat accents, capitalization, brands, hyphens or symbols differently:
iPhone15ProMax256GB
or:
iPhone15ProMax256GB
It looks minor. It is not. It can affect:
- how the context window is consumed;
- how entities are detected;
- how brands and product names are preserved;
- how variants with or without accents are compared;
- how acronyms, models, technical references or prices are represented;
- how long documents are cut into chunks;
- which fragments stay together or get separated;
- which terms carry more weight in the semantic representation.
For GEO this matters a great deal. A brand, product or attribute may tokenize differently depending on the model. GEOdoctor, S.A.M., iPhone 16 Pro, B2C, CX, ISO 27001, A++, Madrid, Mexico or llms.txt may occupy different numbers of tokens and generate non-identical internal representations.
The practical consequence: the same content does not always "fit" equally well in every LLM. A text may be transparent to one model and less legible to another if entities, attributes, structured data or business phrases are not explicit enough. That is why a GEO strategy should not assume that one optimization works identically for ChatGPT, Gemini, Claude, Copilot and Perplexity.
Vectorizing the question and the documents
Next comes the step that makes it possible to compare questions and documents. The user's question and the retrieved fragments are transformed into the same kind of mathematical representation.
The question becomes an embedding:
user question -> vector qEach retrieved fragment also becomes an embedding:
document fragment -> vector dBoth vectors live in a shared semantic space. Thanks to that, the system can compare meaning, not only literal word overlap.
The comparison can be expressed like this:
score = cos(q,d)
semantic distance = 1 - scoreA fragment that does not literally repeat "best phones 2026" can still be highly useful if it discusses performance, camera, battery, price, local availability, user satisfaction or common problems. Matching does not depend only on repeating the keyword. It depends on semantic proximity between the user's need and the retrieved content.
Semantic matching and chunk selection
Once chunks are vectorized, the system searches for the fragments closest to the query using techniques such as ANN or kNN. Then it may apply:
- reranking;
- threshold filters;
- deduplication;
- source diversity;
- date filters;
- language filters;
- consistency validation;
- selection of
top-k chunks.
The goal is to give the model compact, useful and sufficiently diverse context to build an answer.
The LLM does not receive "the whole internet". It receives a limited selection of fragments. That selection shapes the final answer far more than it usually appears from the outside.
How different LLMs do semantic matching and selection
There is no single way to do "LLM semantic matching". Each system mixes different components: lexical search, vector search, embeddings, freshness signals, neural rerankers, intent classifiers, safety filters, product policies and citation preferences.
A typical architecture may include:
-
Lexical retrieval
Matching by terms, entities, brand names, dates, URLs, titles or exact expressions. It is useful for queries with proper nouns:Dexeus,iPhone 16 Pro,GEOdoctor,CaixaBank,Madrid. -
Semantic retrieval
Comparison between query embeddings and chunk embeddings. It finds content that answers the meaning even when it uses different words. -
Hybrid retrieval
A mix of lexical and vector search. It is more resilient to two common failures: losing exact documents because they do not look "semantic" enough, or retrieving semantically similar documents that are factually wrong. -
Reranking
A second model reorders candidates according to expected usefulness for the answer. It may evaluate whether the fragment answers the question, is specific, recent, reliable, evidential or duplicate. -
Context packing
The system decides which chunks fit inside the context window. Two equally relevant fragments may compete when space is limited. -
Answer planning
The LLM decides how to use those fragments: list, comparison, summary, warning, recommendation, table or direct answer.
ChatGPT
ChatGPT can combine external search, web results, fragment retrieval and generative reasoning. When it searches, it does not simply return the top-ranked result. It can reformulate the query, read several results, extract passages and build a synthesis.
Matching may favor:
- recent pages when the question is time-sensitive;
- clear and self-contained fragments;
- sources that solve a specific subquestion;
- content with explicit entities;
- documents that allow several options to be compared;
- sources that reduce uncertainty.
For ChatGPT, GEO-optimized content should be easy to fragment, understand and cite. Tables, FAQs, explicit comparisons, evidence-backed claims and pages with clear dates often help more than a long, polished but ambiguous essay.
Gemini
Gemini can use Google Search for grounding, but it does not replicate the SERP. Its matching may combine signals from the Google ecosystem with generative prompt interpretation. A strong SEO page can become a candidate. The real question is different: do its fragments fit the conversational objective?
Gemini may be especially sensitive to:
- freshness;
- entity clarity;
- relationship with search intent;
- localization signals;
- structured data;
- consensus across sources;
- ability to resolve a comparison.
Simple example: if the user asks best phones for traveling through Europe in 2026, talking about "best phones" is not enough. A fragment that mentions battery life, roaming, eSIM, camera, durability, European price and local availability may match better than a page with general authority.
Claude
Claude must be measured separately. Its behavior cannot be inferred from Google or Bing. In searches with sources, it may select and cite documents, but its synthesis depends heavily on context coherence and the argumentative quality of the sources.
In Claude, content may work better when it:
- avoids ambiguity;
- separates facts, opinions and claims;
- explains reasoning;
- provides enough context;
- keeps terminology consistent;
- presents evidence clearly;
- reduces internal contradictions.
This tends to make it more cautious in recommendations when sources are weak, contradictory or too promotional.
Copilot
Copilot can combine the web, Bing, Microsoft context and, in corporate environments, Microsoft Graph. Its matching changes substantially depending on whether the user is in a public or enterprise environment.
In an enterprise environment, the following may matter:
- internal documents;
- user permissions;
- emails, files or corporate knowledge;
- public web sources;
- productivity context;
- the user's identity and role.
So GEO visibility in Copilot is not only a public-web problem. For B2B brands and institutions, internal documents, knowledge bases, PDFs, presentations, intranets, policies, product sheets and sales materials can also enter the picture.
Perplexity
Perplexity is more oriented toward answering with visible sources. Its matching usually rewards direct, updated, citable content designed to answer without detours. It may select several sources and build an answer with references.
To perform well in Perplexity, a source should be:
- clear in the title;
- explicit in the answer;
- updated;
- easy to cite;
- not excessively blocked;
- useful as evidence;
- specific enough for the query.
In GEO, Perplexity is especially useful for observing which sources the system considers citable in a specific category.
Why domains are not selected only by authority
In classic SEO we often look at domain authority, keywords, backlinks and general ranking. In generative retrieval, that is not enough.
A very strong domain may fail to provide the right fragment for a specific question. A smaller source may become decisive if it contains exactly the passage that matches the user's objective.
The system may evaluate:
- Semantic match: whether the chunk answers the prompt objective.
- Freshness: whether the information is up to date.
- Geographic proximity: whether the source is relevant for Spain, Europe, LATAM or another market.
- Language and localization: whether the content matches the user's real language.
- Customer-persona fit: technical buyer, family user, CMO, patient, student, traveler.
- Purchase factors: price, trust, warranty, availability, reputation.
- Brand attributes: innovation, sustainability, reliability, luxury, security, service.
- Source type: media, review platform, official website, forum, marketplace, technical documentation.
- Consistency: whether independent sources confirm the same point.
- Sentiment: whether the source improves or weakens brand perception.
- Crawlability: whether the content is easy to read, extract, index and cite.
- Structured data: schema, tables, FAQs, metadata, dates, authorship and clear entities.
The consequence is uncomfortable for many inherited strategies: in GEO, the biggest domain does not necessarily win. The winning content is the content the system can find, understand, compare and use to solve a specific question.
UGC sources inside the GEO flow
UGC layers have a particular role inside this system. They are not usually the only source of an answer, but they can act as validation signals when the user asks about trust, service quality, satisfaction, frequent problems or comparison between brands.
For an LLM, a real-user experience source can provide:
- evidence of real user experience;
- natural language about problems and benefits;
- aggregated sentiment;
- recurrence signals;
- customer-persona vocabulary;
- brand attributes that do not appear on the official website;
- contrast against the brand's commercial claim.
This explains why reviews matter in GEO even when they are not always the most cited source. Sometimes their value is not in appearing as the main link, but in confirming or challenging what other sources say about the brand.
A brand with good corporate content but weak or contradictory reviews may receive more cautious answers. A brand with limited media presence but clear satisfaction signals in review sources may reinforce attributes such as trust, service, reliability or value for money.
Technical validation of sources in the main LLMs
Source validation is not uniform either. Each system decides in its own way what is sufficient, reliable, fresh, citable or useful.
A validation layer may evaluate:
- Recency: publication date, update date, topic volatility.
- Entity: whether the source correctly identifies the brand, product, person, institution or location.
- Authorship: visible author, responsible organization, sector reputation.
- Evidence: data, tables, methodology, examples, cases, citations, documentation.
- Consistency: whether the fragment matches other retrieved sources.
- Conflict: whether there are contradictions, complaints, controversies or recent changes.
- Sentiment: positive, neutral, negative, defensive or critical tone.
- Citability: whether the source can be cited clearly and stably.
- Crawler accessibility: whether the content is available to bots without relying on scripts, images or unnecessary walls.
- Specificity: whether it answers the concrete question or only provides generic information.
- Contextual fit: whether it fits market, language, persona, product line and intent.
ChatGPT
ChatGPT may evaluate retrieved sources according to usefulness for the answer, freshness, coherence and ability to solve the question. In products with citations, it also needs to select sources it can show the user as support.
A source may be excluded even if it is well known when:
- the fragment does not answer the question;
- it is outdated;
- it is too promotional;
- it provides no evidence;
- it contradicts more specific sources;
- it does not fit the user's market;
- it is not useful for the generated subquestion.
Gemini
Gemini with Grounding can rely on Google Search, but generative validation prioritizes fragments that fit intent, freshness and consistency. SEO strength helps a page enter the candidate set. It does not guarantee inclusion in the answer.
Gemini may behave differently for:
- local searches;
- YMYL topics;
- commercial queries;
- comparative prompts;
- date-sensitive questions;
- brand entities with conflicting information.
Claude
Claude tends to be more cautious when sources are unclear or when retrieved context does not support a strong conclusion. In validation, that leads to more nuanced, less categorical answers that depend more on contrasts between sources.
For GEO, the practical reading is direct: a brand must provide clear evidence, not only claims. Claude may penalize ambiguous, overly commercial or hard-to-verify content.
Copilot
Copilot can validate web sources alongside internal sources when it operates inside a Microsoft environment. In that case, relevance does not depend only on the public web. Permissions, corporate context, internal documents, calendar, email, files and knowledge bases also count.
A brand may be well represented on the open web but appear differently in Copilot if the user works inside an enterprise ecosystem with outdated, contradictory or incomplete internal documentation.
Perplexity
Perplexity tends to show sources visibly. Citability matters a lot. A clear, current and specific source may have an advantage over a broader but less direct one.
For GEO, Perplexity makes it easier to observe which URLs it considers useful support for an answer. That makes it a good system for analyzing citable source maps by category.
Source validation
Before generating the final answer, the system may evaluate contextual authority, freshness, consistency, conflicts between sources, sentiment, affinity with the question and real usefulness for the user.
It may also detect contradictory sources. For example:
- an official website claims a benefit;
- a review platform shows recurring complaints;
- an industry outlet validates an advantage;
- a forum introduces negative sentiment;
- a local comparison favors a competitor.
The final answer is built from that tension between sources. That is why a brand should not obsess only about "appearing". The better question is more precise: which fragments appear, how each LLM represents them, with which sentiment, for which customer persona they are relevant, and in which context they are available to generative systems.
Answer construction
Once the relevant fragments have been selected, the LLM builds the answer by combining:
- the user's original prompt;
- the semantic interpretation of the task;
- the retrieved chunks;
- system instructions;
- safety policies;
- generation parameters;
- expected style;
- token limit;
- temperature;
- top-p.
The answer is not a copy of the sources. It is a generative synthesis. The model summarizes, compares, orders, softens uncertainty and decides what to omit and what to emphasize. That is why the final result depends both on the retrieved documents and on how the model interprets their relevance.
Where GeoRadar enters
This is where GeoRadar stops being a reporting tool and becomes a research tool.
If we launch thousands of personalized prompts crossed by customer persona, market, product line, intent, purchase factors and competitors, and we also use a system that checks whether those questions cover the real business space, we can stimulate AI in a way very similar to how real users would during ordinary sessions.
Then we store and analyze those conversations. This reveals which sources LLMs retrieve again and again, how visible and recommended we are, which attributes they associate with our brand, what sentiment they use, how they compare us with competitors, in which markets we appear better or worse, and which content, reputation or authority gaps are shaping the answers.
The result is no longer a single screenshot. It is a traceable map of how generative models understand, validate and recommend a brand inside its category.
Why volume matters
One isolated conversation does not diagnose a market. A prompt may be biased by wording, session, model, timing or search configuration.
To read the market reliably, you need volume and semantic coverage. That means building a broad dataset that crosses:
- customer personas;
- markets;
- languages;
- product lines;
- funnel stages;
- intents;
- purchase factors;
- competitors;
- brand attributes;
- informational, comparative, transactional and skeptical prompts.
When that volume is combined with a completeness algorithm, the system can detect whether the question map sufficiently covers the real decision space. That is the difference between running a curious test and building a GEO audit with business value.
The critical point
In GEO, data without precision and volume has little value. Publishing a lot without knowing what, how and for whom is shooting blind.
The advantage appears when a brand knows which questions activate its category, which sources feed the answers, which attributes are assigned to it, which competitors occupy its space, and which content must be created, corrected or activated so the brand can be understood, validated and recommended by generative models.
From diagnosis to brand and business impact
To create real brand and business impact, an excellent study is not enough. Diagnosis is the first layer. Then you need a well-prioritized action plan and tools to execute it with the right scale, precision and speed.
GEO work must convert market reading into operational decisions:
- which sources to activate first;
- which content to create;
- which content to correct;
- which knowledge gaps to close;
- which attributes to reinforce;
- which markets to prioritize;
- which customer personas to target;
- which competitors to displace;
- which prompts should start returning a different answer.
Prioritization cannot be generic. Sources must be ranked by expected return against effort and investment. One source may have strong semantic influence but require too much cost. Another may have less global weight and still offer immediate return if it helps validate a business attribute, correct negative sentiment or gain presence in a specific market.
You also need realistic technical GEO with measurable return. Not everything is fixed by publishing content. Sometimes the problem is that the website is not easy for crawlers to read, does not expose entities well, structures data poorly, uses the wrong schema, hides critical information in inaccessible assets, or does not provide clean routes for bots to understand products, services, experts, locations, cases and claims.
The content strategy must be prioritized according to brand objectives. Two areas deserve particular attention:
- Knowledge gaps: what LLMs do not know, cannot find or misinterpret about the brand.
- Competitive benchmark: what competitors already occupy across prompts, sources, attributes, recommendations and markets.
There is another point: content should not be created only to please humans or cover keywords. It must fit the vector value that AI bots look for when they compare a question with the fragments available. That requires content aligned with specific prompts, specific customer personas and specific business attributes.
That is why tools are needed to evaluate content before publication, help create it quickly and show which prompts it is designed to serve. Writing an article about a topic is not enough. You need to know whether that article has a real probability of being retrieved, understood and used by the model to build an answer.
Conversational behavior also has to be analyzed. A brand may appear well in the first prompt and disappear when the second, third or fourth prompt arrives in the same conversation. That matters because many users do not decide with a single question. They compare, ask follow-ups, request alternatives, filter by price, location, trust, specific use case or reputational doubt.
The opportunity is large: increasing conversion in a scenario where organic web traffic is consistently falling and where more decisions start, advance or close inside generative interfaces. GEO opens a new discipline. It is not only about attracting visits. It is about being recommended when the user is already asking for help deciding.
Being recommended by generative models means competing for the attention and trust of more than one billion users. Naturally, this requires new tools, new methods and a different way to connect data, content, sources, technology and business.
Technical sources consulted
- OpenAI Help Center: ChatGPT Search, external search providers and query handling.
- OpenAI: Introducing ChatGPT Search, description of ChatGPT Search and external providers.
- OpenAI Help Center: What are tokens and how to count them?, tokenization and variation by model/encoding.
- Google AI for Developers: Grounding with Google Search, Gemini connection with real-time web content.
- Google AI for Developers: Understand and count tokens, tokenization and token counting in Gemini.
- Microsoft Learn: Grounding with Bing Search, generated query flow, Bing results and final model answer.
- Microsoft Learn: Data, privacy, and security for web search in Microsoft 365 Copilot, queries generated by Copilot and sent to Bing.
- Anthropic Docs: Web search tool, web search, results and citations in Claude.
- Perplexity Docs: Search API, structured results and differences with Sonar.
- Perplexity Docs: Sonar API, web-grounded answers with
search_resultsand citations.