Cuando un usuario pregunta algo que exige datos recientes, un LLM no responde solo desde su memoria interna. Puede activar sistemas de búsqueda, recuperar fragmentos de la web, compararlos semánticamente, validar fuentes y construir una respuesta con información actualizada.
La pregunta de fondo es técnica: ¿cómo pasa un LLM de un prompt escrito por un usuario a una respuesta fundamentada en documentos, resultados de búsqueda y fragmentos recuperados en tiempo real?
Este artículo explica ese flujo. Sirve para entender por qué ChatGPT, Gemini, Claude, Copilot o Perplexity pueden responder de forma distinta a la misma pregunta, por qué no todos valoran igual las mismas fuentes y por qué la optimización para LLMs no consiste en publicar más, sino en entender qué fragmentos recuperan los modelos, para qué intención y dentro de qué contexto.
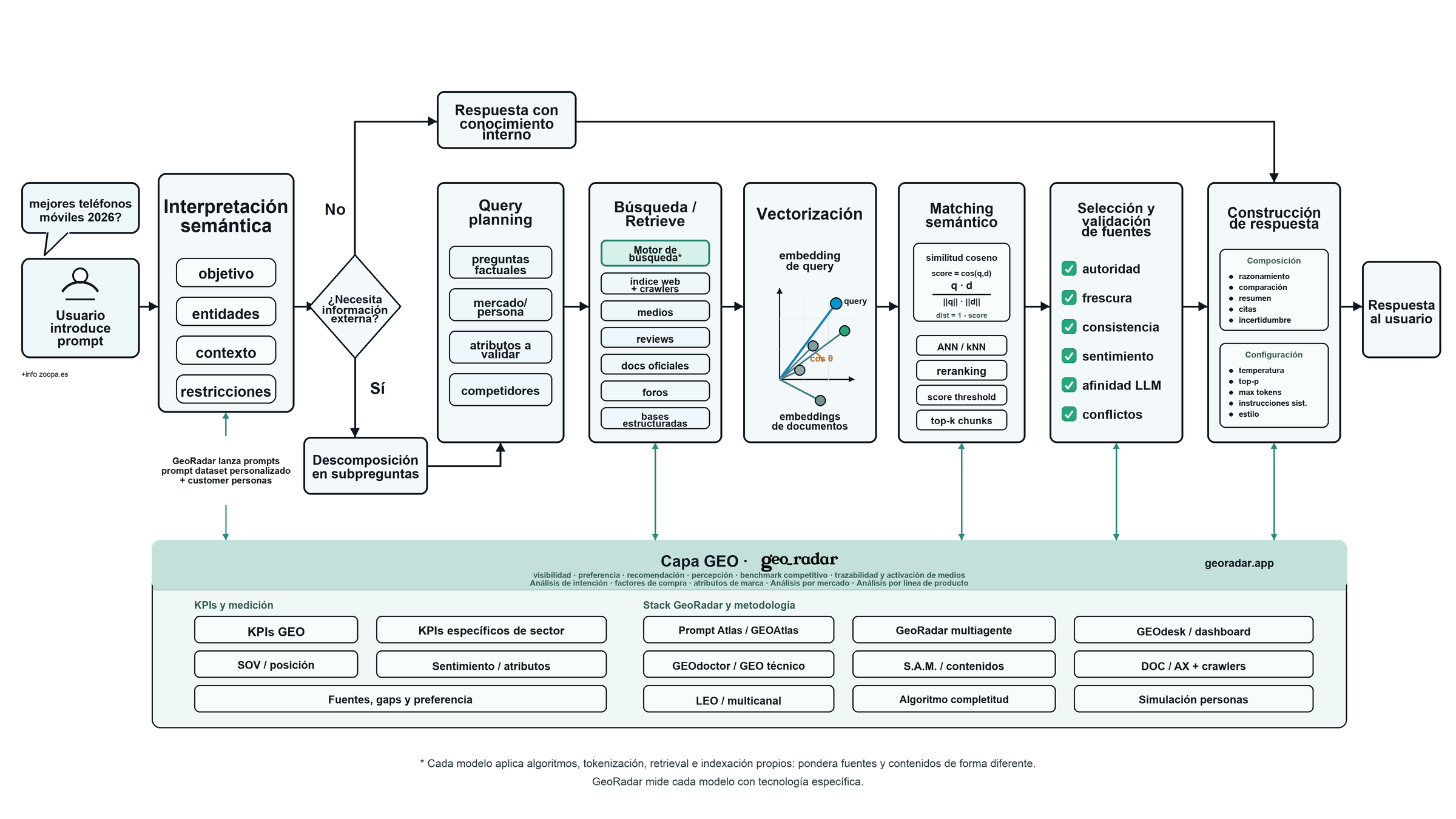
Diagrama en alta resolución: prompt, query planning, retrieve, vectorización, matching semántico, validación de fuentes y construcción de respuesta.
Idea central
Un LLM rara vez responde a una pregunta compleja "de golpe". Antes hace algo bastante parecido a ordenar la mesa: interpreta qué se le está pidiendo, detecta entidades, mira el contexto de la conversación y decide si puede responder con lo que ya sabe o si necesita salir a buscar información.
Cuando necesita datos actuales, entra en juego otra maquinaria: búsqueda, crawling, recuperación de fragmentos, comparación semántica, validación de fuentes y, al final, composición de la respuesta.
Aquí está la parte importante para GEO. Muchas respuestas no salen solo del conocimiento preentrenado del modelo. Salen de una mezcla de razonamiento, recuperación, fuentes encontradas y criterios internos de composición. OpenAI documenta, por ejemplo, que ChatGPT Search puede decidir buscar en la web según lo que pregunte el usuario, o permitir que el usuario active la búsqueda manualmente.
En cualquier categoría donde importan actualidad, comparación o decisión, eso cambia las reglas. Una respuesta sobre "mejores bancos para jóvenes", "móviles con mejor servicio postventa" o "marcas de moda fiables en España" puede estar condicionada por fragmentos recuperados en medios, webs oficiales, comparativas, foros, documentación técnica, marketplaces o reseñas de usuarios.
Qué ocurre cuando el usuario pregunta
Si alguien escribe mejores teléfonos móviles 2026, el modelo no está leyendo solo cuatro palabras. Está leyendo una intención de compra. Hay comparación, actualidad, riesgo de obsolescencia, marcas candidatas, posibles rangos de precio y una expectativa bastante clara: el usuario quiere una recomendación, no una definición de qué es un móvil.
El sistema analiza:
- objetivo de respuesta;
- entidades mencionadas o implícitas;
- contexto conversacional;
- mercado, idioma y fecha;
- restricciones explícitas;
- criterios implícitos de valor;
- factores de compra;
- atributos de marca relevantes;
- nivel de actualidad requerido.
Ese matiz cambia todo lo que viene después.
Decisión de búsqueda
El modelo, o la capa que lo orquesta, decide si puede contestar con conocimiento interno o si necesita información externa. En preguntas actuales, comparativas, transaccionales, reputacionales o muy pegadas a un mercado concreto, lo habitual es que se active alguna forma de recuperación: búsqueda web, consulta a índices, conectores o fuentes estructuradas.
La decisión puede depender de:
- actualidad de la pregunta;
- presencia de fechas como
2026; - necesidad de precios, disponibilidad o novedades;
- riesgo de información obsoleta;
- necesidad de comparar marcas;
- necesidad de citar o validar fuentes;
- probabilidad de que el usuario espere datos recientes.
Si se activa la búsqueda, el prompt original se convierte en un conjunto de subpreguntas.
Ejemplo:
- mejores smartphones 2026;
- móviles con mejor cámara;
- comparativa iPhone Samsung Xiaomi;
- opiniones de usuarios sobre batería;
- mejores móviles para comprar en España;
- problemas frecuentes por modelo;
- marcas más recomendadas por segmento de precio.
En una consulta reputacional o comercial, esa descomposición puede incluir búsquedas como:
- valoraciones de usuarios sobre una marca;
- quejas frecuentes por servicio;
- valoración media en plataformas de reseñas;
- experiencia de usuario en foros;
- comparativas con competidores;
- reseñas verificadas en plataformas especializadas.
Motores de búsqueda y grounding por modelo
Hay una confusión muy común: pensar que si un LLM usa Bing, Google Search u otro sistema de recuperación, entonces funciona como ese buscador. No es así.
El buscador puede aportar URLs, snippets, documentos o pasajes. Luego el modelo hace otra cosa: reinterpreta, comprime, compara, descarta y convierte todo eso en una respuesta conversacional.
Por eso, aunque dos sistemas consulten fuentes parecidas, pueden terminar generando respuestas diferentes.
ChatGPT
OpenAI documenta que ChatGPT Search puede usar proveedores externos de búsqueda, incluido Bing, junto con otros partners y contenidos recuperados. Pero ChatGPT no es Bing con una interfaz conversacional encima.
La búsqueda encuentra candidatos. ChatGPT decide qué consultar, cómo reformular la pregunta, qué fragmentos usar, cómo sintetizarlos y cómo responder según sus instrucciones, el contexto de la conversación y sus políticas.
En uso real, ChatGPT puede:
- decidir si busca o no busca;
- generar una o varias consultas;
- recuperar resultados web;
- abrir o sintetizar fuentes;
- combinar pasajes;
- citar resultados cuando el producto lo permite;
- componer una respuesta con estilo conversacional.
El resultado no es un ranking de Bing pegado en pantalla. Es una respuesta generativa condicionada por búsqueda.
Gemini
Google documenta Grounding with Google Search para Gemini. Eso significa que Gemini puede fundamentar una respuesta con resultados de Google Search. Pero tampoco convierte a Gemini en el buscador clásico de Google.
Google Search puede actuar como infraestructura de recuperación. Gemini sigue aplicando su propia lectura del prompt, su sistema de contexto, sus mecanismos de grounding, sus filtros y su generación final.
Aquí hay una trampa para equipos SEO: una página puede posicionar bien en Google Search y aun así no ser el fragmento que Gemini decide usar en una respuesta generativa. Para entrar en la respuesta, la página debe ser recuperable, clara, estructurada y útil para ese objetivo conversacional concreto.
Microsoft Copilot
Microsoft Copilot se apoya de forma natural en el ecosistema Bing y Microsoft. En entornos empresariales puede mezclar web, Microsoft Graph, documentos corporativos, conectores y permisos del usuario.
Microsoft documenta agentes y experiencias de grounding con Bing Search, pero el resultado final tampoco es una SERP. Copilot transforma el prompt en consultas, recupera información, aplica contexto corporativo cuando lo tiene disponible y genera una respuesta.
Para GEO esto importa mucho. El mismo contenido puede comportarse de forma distinta en Copilot si se evalúa en modo web abierto, dentro de un tenant corporativo, con Microsoft Graph disponible o con conectores internos activos.
Claude
Anthropic documenta capacidades de web search para Claude, con recuperación de información actual y citas. A diferencia de ChatGPT/Bing o Gemini/Google Search, las fuentes públicas no permiten reducir Claude a un motor externo concreto.
Lo que sí sabemos es suficiente para medirlo por separado: Claude tiene su propio sistema de búsqueda, selección de fuentes, citas, razonamiento sobre documentos y políticas de respuesta.
Suele ser especialmente sensible a la calidad del contexto, la claridad documental, la consistencia de las fuentes y la forma en que se presenta la evidencia. En un estudio GEO, inferir Claude desde ChatGPT o Gemini es una mala idea.
Perplexity
Perplexity se presenta como un sistema answer-first y search-native. Sus productos Sonar y Search API trabajan con búsqueda web, recuperación y citas. La experiencia está pensada para responder con fuentes visibles, aunque eso no quiere decir que seleccione las mismas fuentes ni que las pese igual que Google, Bing, ChatGPT o Gemini.
En Perplexity, una fuente gana valor cuando responde de forma directa, actual, verificable y citable. Para GEO, eso da mucho peso a páginas limpias, actualizadas, bien tituladas, con información explícita y poca ambigüedad.
Lo que importa para GEO
Cada modelo tiene una arquitectura distinta:
- distinto motor o proveedor de búsqueda;
- distinta forma de generar queries;
- distinto sistema de tokenización;
- distinto modelo de embeddings;
- distinta política de chunking;
- distinta ventana de contexto;
- distinto reranking;
- distinta tolerancia a fuentes contradictorias;
- distinta forma de citar;
- distinto estilo de síntesis;
- distintas políticas de seguridad y marca.
La lectura operativa es sencilla: no basta con preguntar una vez a un único LLM. Una auditoría GEO seria mide cada modelo, cada mercado y cada customer persona por separado.
Búsqueda, crawling y recuperación
El sistema no lee internet como lo haría una persona. Tampoco como lo hace el buscador de Google cuando devuelve una SERP. Consulta motores, índices propios, crawlers, bases documentales, fuentes estructuradas o conectores específicos.
Y cada LLM resuelve esta capa a su manera. ChatGPT, Gemini, Claude, Copilot y Perplexity no indexan igual, no recuperan igual y no ponderan los resultados con los mismos criterios.
El proceso suele tener cuatro piezas:
-
Query planning
El prompt se transforma en varias queries orientadas a resolver partes del problema. -
Crawling o consulta de índices
Los crawlers y motores recuperan páginas candidatas, documentos, tablas, reviews, FAQs, fichas técnicas, medios, foros, documentación oficial o datos estructurados. -
Extracción de fragmentos
El sistema no trabaja principalmente con dominios completos. Extrae piezas de contenido: títulos, párrafos, listas, tablas, bloques de producto, fragmentos de review, respuestas de FAQ, schema markup, fechas, autores, entidades, idioma y señales de localización. -
Chunking y normalización
El contenido se limpia y se divide en chunks: fragmentos manejables que conservan significado. Un chunk puede ser un párrafo de una review, una tabla de precios, una ficha técnica, una comparativa o un bloque de opiniones de usuarios.
Tokenización: por qué cada LLM representa la información de forma distinta
Antes de vectorizar o generar una respuesta, el modelo parte el texto en unidades internas: tokens. A veces un token es una palabra. A veces es media palabra, un signo, una secuencia frecuente o una pieza subléxica.
Y aquí aparece una diferencia poco visible, pero enorme: cada familia de modelos tokeniza a su manera. OpenAI usa tokenizadores como los de la familia tiktoken. Google ofrece herramientas de conteo de tokens para Gemini. Anthropic documenta su propio conteo para Claude. Cada sistema tiene vocabulario, límites de contexto y forma de trocear texto.
El modelo, por tanto, no ve exactamente "palabras". Ve secuencias de tokens.
Ejemplo conceptual:
mejores teléfonos móviles 2026
Un modelo puede dividirlo de forma parecida a:
mejoresteléfonosmóviles2026
Otro puede partirlo de forma más granular:
mejoresteléfonosmóviles2026
Otro puede tratar acentos, mayúsculas, marcas, guiones o símbolos de forma diferente:
iPhone15ProMax256GB
o:
iPhone15ProMax256GB
Parece una diferencia menor. No lo es. Puede afectar a:
- cómo se consume la ventana de contexto;
- cómo se detectan entidades;
- cómo se preservan marcas y nombres de producto;
- cómo se comparan variantes con o sin acentos;
- cómo se representan siglas, modelos, referencias técnicas o precios;
- cómo se cortan documentos largos en chunks;
- qué fragmentos quedan juntos o separados;
- qué términos tienen más peso en la representación semántica.
Para GEO esto pesa mucho. Una marca, un producto o un atributo pueden tokenizarse de forma distinta según el modelo. GEOdoctor, S.A.M., iPhone 16 Pro, B2C, CX, ISO 27001, A++, Madrid, México o llms.txt pueden ocupar diferentes números de tokens y generar representaciones internas no idénticas.
La consecuencia práctica: el mismo contenido no siempre "encaja" igual en todos los LLMs. Un texto puede ser transparente para un modelo y menos legible para otro si las entidades, los atributos, los datos estructurados o las frases de negocio no están suficientemente explícitas. Por eso una estrategia GEO no debería asumir que una optimización sirve igual para ChatGPT, Gemini, Claude, Copilot y Perplexity.
Vectorización de la pregunta y de los documentos
Después viene el paso que permite comparar preguntas y documentos. La pregunta del usuario y los fragmentos recuperados se transforman al mismo tipo de representación matemática.
La pregunta se convierte en un embedding:
pregunta del usuario -> vector qCada fragmento recuperado se convierte también en un embedding:
fragmento de documento -> vector dAmbos vectores viven en un espacio semántico común. Gracias a eso se puede comparar significado, no solo coincidencia literal de palabras.
La comparación puede expresarse así:
score = cos(q,d)
distancia semántica = 1 - scoreUn fragmento que no repite literalmente "mejores móviles 2026" puede ser muy útil si habla de rendimiento, cámara, batería, precio, disponibilidad local, satisfacción de usuarios o problemas frecuentes. El matching no depende solo de repetir la keyword. Depende de la proximidad semántica entre la necesidad del usuario y el contenido recuperado.
Matching semántico y selección de chunks
Una vez vectorizados los chunks, el sistema busca los fragmentos más cercanos a la query mediante técnicas como ANN o kNN. Luego puede aplicar:
- reranking;
- filtros de umbral;
- deduplicación;
- diversidad de fuentes;
- filtros por fecha;
- filtros por idioma;
- validación de consistencia;
- selección de
top-k chunks.
La idea es entregar al modelo un contexto compacto, útil y suficientemente diverso para construir una respuesta.
El LLM no recibe "todo internet". Recibe una selección limitada de fragmentos. Esa selección condiciona la respuesta final mucho más de lo que suele parecer desde fuera.
Cómo hacen el matching semántico y la selección los distintos LLMs
No existe una única forma de hacer "matching semántico de LLMs". Cada sistema mezcla piezas distintas: búsqueda léxica, búsqueda vectorial, embeddings, señales de frescura, rerankers neuronales, clasificadores de intención, filtros de seguridad, políticas de producto y preferencias de citabilidad.
La arquitectura típica puede incluir:
-
Retrieval léxico
Coincidencia por términos, entidades, nombres de marca, fechas, URLs, títulos o expresiones exactas. Es útil para queries con nombres propios:Dexeus,iPhone 16 Pro,GEOdoctor,CaixaBank,Madrid. -
Retrieval semántico
Comparación entre embeddings de la query y embeddings de chunks. Encuentra contenido que responde al significado aunque use otras palabras. -
Hybrid retrieval
Mezcla búsqueda léxica y vectorial. Es más resistente a dos fallos típicos: perder documentos exactos porque no parecen suficientemente "semánticos", o recuperar documentos parecidos en significado pero factualmente incorrectos. -
Reranking
Un segundo modelo reordena los candidatos según utilidad esperada para la respuesta. Puede valorar si el fragmento responde a la pregunta, si es específico, si es reciente, si es fiable, si aporta evidencia o si duplica información ya recuperada. -
Context packing
El sistema decide qué chunks caben en la ventana de contexto. Dos fragmentos igual de relevantes pueden competir si el espacio es limitado. -
Answer planning
El LLM decide cómo usar esos fragmentos: lista, comparación, resumen, advertencia, recomendación, tabla o respuesta directa.
ChatGPT
ChatGPT puede combinar búsqueda externa, resultados web, recuperación de fragmentos y razonamiento generativo. Cuando busca, no se limita a devolver el resultado mejor posicionado. Puede reformular la query, leer varios resultados, extraer pasajes y construir una síntesis.
El matching puede favorecer:
- páginas recientes cuando la pregunta es temporal;
- fragmentos claros y autocontenidos;
- fuentes que resuelven una subpregunta concreta;
- contenido con entidades explícitas;
- documentos que permiten contrastar varias opciones;
- fuentes que reducen incertidumbre.
Para ChatGPT, un contenido optimizado para GEO debe ser fácil de fragmentar, entender y citar. Tablas, FAQs, comparativas explícitas, claims con evidencia y páginas con fechas claras suelen ayudar más que una pieza larga, bonita y ambigua.
Gemini
Gemini puede apoyarse en Google Search para grounding, pero no replica la SERP. Su matching puede combinar señales del ecosistema Google con interpretación generativa del prompt. Una página fuerte en SEO puede ser candidata. La pregunta de verdad es otra: ¿sus fragmentos encajan con el objetivo conversacional?
Gemini puede ser especialmente sensible a:
- actualidad;
- claridad de entidades;
- relación con la intención de búsqueda;
- señales de localización;
- datos estructurados;
- consenso entre fuentes;
- capacidad de una página para resolver una comparación.
Ejemplo sencillo: si el usuario pregunta mejores móviles para viajar por Europa en 2026, no basta con hablar de "mejores móviles". Un fragmento que menciona batería, roaming, eSIM, cámara, resistencia, precio europeo y disponibilidad local puede tener más match que una página con autoridad general.
Claude
Claude debe medirse aparte. Su comportamiento no se deduce de Google ni de Bing. En búsquedas con fuentes puede seleccionar y citar documentos, pero su forma de sintetizar depende mucho de la coherencia del contexto y de la calidad argumental de las fuentes.
En Claude, un contenido puede funcionar mejor si:
- evita ambigüedades;
- separa hechos, opiniones y claims;
- explica el razonamiento;
- ofrece contexto suficiente;
- mantiene consistencia terminológica;
- presenta evidencia de forma clara;
- reduce contradicciones internas.
Esto tiende a volverlo más prudente en recomendaciones cuando las fuentes son débiles, contradictorias o demasiado promocionales.
Copilot
Copilot puede mezclar web, Bing, contexto de Microsoft y, en entornos corporativos, Microsoft Graph. Su matching cambia bastante según si el usuario está en un entorno público o empresarial.
En un entorno empresarial, puede pesar:
- documentos internos;
- permisos de usuario;
- correos, archivos o conocimiento corporativo;
- fuentes web públicas;
- contexto de productividad;
- identidad y rol del usuario.
Así que la visibilidad GEO en Copilot no es solo un problema de web pública. Para marcas B2B o instituciones también entran en juego documentos internos, knowledge bases, PDFs, presentaciones, intranets, políticas, fichas y materiales comerciales.
Perplexity
Perplexity está más orientado a responder con fuentes visibles. Su matching suele premiar contenido directo, actualizado, citable y pensado para contestar sin rodeos. Puede seleccionar varias fuentes y construir una respuesta con referencias.
Para aparecer bien en Perplexity, una fuente debe ser:
- clara en el título;
- explícita en la respuesta;
- actualizada;
- fácilmente citable;
- no excesivamente bloqueada;
- útil como evidencia;
- suficientemente específica para la query.
En GEO, Perplexity es especialmente útil para observar qué fuentes el sistema considera citables en una categoría concreta.
Por qué no se seleccionan dominios solo por autoridad
En SEO clásico solemos mirar autoridad de dominio, keywords, backlinks y ranking general. En retrieval generativo eso se queda corto.
Un dominio muy fuerte puede no aportar el fragmento adecuado para una pregunta concreta. Y una fuente más pequeña puede acabar siendo decisiva si contiene justo el pasaje que encaja con el objetivo del usuario.
El sistema puede valorar:
- Match semántico: si el chunk responde exactamente al objetivo del prompt.
- Frescura: si la información está actualizada.
- Proximidad geográfica: si la fuente es relevante para España, Europa, LATAM u otro mercado.
- Idioma y localización: si el contenido coincide con el idioma real del usuario.
- Adecuación a la customer persona: comprador técnico, usuario familiar, CMO, paciente, estudiante, viajero.
- Factores de compra: precio, confianza, garantía, disponibilidad, reputación.
- Atributos de marca: innovación, sostenibilidad, fiabilidad, lujo, seguridad, servicio.
- Tipo de fuente: medio, review platform, web oficial, foro, marketplace, documentación técnica.
- Consistencia: si varias fuentes independientes confirman el mismo punto.
- Sentimiento: si la fuente refuerza o deteriora la percepción de marca.
- Crawlability: si el contenido es fácil de leer, extraer, indexar y citar.
- Datos estructurados: schema, tablas, FAQs, metadatos, fechas, autoría y entidades claras.
La consecuencia es bastante incómoda para muchas estrategias heredadas: en GEO no gana necesariamente el dominio más grande. Gana el contenido que el sistema puede encontrar, entender, comparar y usar para resolver una pregunta concreta.
Fuentes UGC dentro del flujo GEO
Las capas de UGC tienen un papel particular dentro de este sistema. No suelen ser la única fuente de una respuesta, pero pueden funcionar como señal de validación cuando el usuario pregunta por confianza, calidad de servicio, satisfacción, problemas frecuentes o comparación entre marcas.
Para un LLM, una fuente de experiencia real de usuarios puede aportar:
- evidencia de experiencia real de usuarios;
- lenguaje natural sobre problemas y beneficios;
- sentimiento agregado;
- señales de recurrencia;
- vocabulario de customer persona;
- atributos de marca que no aparecen en la web oficial;
- contraste frente al claim comercial de la marca.
Esto explica por qué las reviews importan en GEO aunque no siempre sean la fuente más citada. A veces su valor no está en aparecer como enlace principal, sino en confirmar o tensionar lo que otras fuentes dicen sobre la marca.
Una marca con buen contenido corporativo, pero reviews débiles o contradictorias, puede recibir respuestas más prudentes. Una marca con presencia mediática discreta, pero señales de satisfacción claras y bien estructuradas en fuentes de reviews, puede reforzar atributos como confianza, servicio, fiabilidad o relación calidad-precio.
Validación técnica de fuentes en los principales LLMs
La validación de fuentes tampoco es uniforme. Cada sistema decide a su manera qué considera suficiente, fiable, fresco, citable o útil.
Una capa de validación puede valorar:
- Recencia: fecha de publicación, fecha de actualización, volatilidad del tema.
- Entidad: si la fuente identifica correctamente marca, producto, persona, institución o ubicación.
- Autoría: autor visible, organización responsable, reputación sectorial.
- Evidencia: datos, tablas, metodología, ejemplos, casos, citas, documentación.
- Consistencia: si el fragmento coincide con otras fuentes recuperadas.
- Conflictividad: si hay contradicciones, quejas, controversias o cambios recientes.
- Sentimiento: tono positivo, neutro, negativo, defensivo o crítico.
- Citabilidad: si la fuente se puede citar de forma clara y estable.
- Accesibilidad crawler: si el contenido está disponible para bots, sin depender de scripts, imágenes o muros innecesarios.
- Especificidad: si responde a la pregunta concreta o solo ofrece información genérica.
- Adecuación contextual: si encaja con mercado, idioma, persona, línea de producto e intención.
ChatGPT
ChatGPT puede valorar fuentes recuperadas según utilidad para la respuesta, actualidad, coherencia y capacidad de resolver la pregunta. En productos con citas, además, necesita seleccionar fuentes que pueda mostrar al usuario como respaldo.
Una fuente puede quedar fuera aunque sea conocida si:
- el fragmento no responde a la pregunta;
- está desactualizado;
- es demasiado promocional;
- no aporta evidencia;
- contradice fuentes más específicas;
- no encaja con el mercado del usuario;
- no es útil para la subpregunta generada.
Gemini
Gemini con Grounding puede apoyarse en Google Search, pero la validación generativa prioriza fragmentos que encajan con intención, actualidad y consistencia. La fuerza SEO de una página ayuda a entrar en el conjunto de candidatos. No garantiza aparecer en la respuesta.
Gemini puede comportarse de forma distinta ante:
- búsquedas locales;
- temas YMYL;
- consultas comerciales;
- prompts comparativos;
- preguntas con fecha;
- entidades de marca con información conflictiva.
Claude
Claude tiende a ser más prudente cuando las fuentes no son claras o cuando el contexto recuperado no permite una conclusión sólida. En validación, eso se traduce en respuestas más matizadas, menos categóricas y más dependientes del contraste entre fuentes.
Para GEO, la lectura es práctica: una marca debe aportar evidencia clara, no solo claims. Claude puede castigar contenido ambiguo, excesivamente comercial o difícil de verificar.
Copilot
Copilot puede validar fuentes web junto con fuentes internas cuando opera en un entorno Microsoft. En ese caso, la relevancia no depende solo de la web pública. También cuentan permisos, contexto corporativo, documentos internos, calendario, correo, archivos y knowledge bases.
Una marca puede estar bien representada en web abierta, pero aparecer de forma distinta en Copilot si el usuario trabaja dentro de un ecosistema empresarial con documentación interna desactualizada, contradictoria o incompleta.
Perplexity
Perplexity tiende a mostrar fuentes de forma visible. La citabilidad pesa mucho. Una fuente clara, actual y específica puede tener ventaja sobre otra más amplia, pero menos directa.
Para GEO, Perplexity permite observar con claridad qué URLs considera útiles como apoyo a una respuesta. Eso lo convierte en un buen sistema para analizar mapas de fuentes citables por categoría.
Validación de fuentes
Antes de generar la respuesta final, el sistema puede valorar autoridad contextual, frescura, consistencia, conflictos entre fuentes, sentimiento, afinidad con la pregunta y utilidad real para el usuario.
También puede detectar si existen fuentes contradictorias. Por ejemplo:
- una web oficial afirma un beneficio;
- una review platform muestra quejas recurrentes;
- un medio sectorial valida una ventaja;
- un foro introduce sentimiento negativo;
- una comparativa local favorece a un competidor.
La respuesta final se construye a partir de esa tensión entre fuentes. Por eso una marca no debería obsesionarse solo con "aparecer". La pregunta buena es más concreta: qué fragmentos aparecen, cómo los representa cada LLM, con qué sentimiento, para qué customer persona resultan relevantes y en qué contexto están disponibles para los sistemas generativos.
Construcción de respuesta
Una vez seleccionados los fragmentos relevantes, el LLM elabora la respuesta combinando:
- el prompt original del usuario;
- la interpretación semántica de la tarea;
- los chunks recuperados;
- las instrucciones del sistema;
- políticas de seguridad;
- parámetros de generación;
- estilo esperado;
- límite de tokens;
- temperatura;
- top-p.
La respuesta no es una copia de las fuentes. Es una síntesis generativa. El modelo resume, compara, ordena, suaviza incertidumbres y decide qué omite y qué destaca. Por eso el resultado final depende tanto de los documentos recuperados como de la forma en que el modelo interpreta su relevancia.
Dónde entra GeoRadar
Aquí es donde GeoRadar deja de ser una herramienta de reporting y se convierte en una herramienta de investigación.
Si lanzamos miles de prompts personalizados, cruzados por customer persona, mercado, línea de producto, intención, factores de compra y competidores, y además usamos un sistema que comprueba que esas preguntas cubren el espacio real del negocio, podemos estimular a la IA de una forma muy parecida a como lo harían usuarios reales en sesiones ordinarias.
Después guardamos y analizamos esas conversaciones. Ahí se ve qué fuentes recuperan los LLMs una y otra vez, cuán visibles y recomendados somos, qué atributos asocian a nuestra marca, con qué sentimiento hablan de nosotros, cómo nos comparan con la competencia, en qué mercados aparecemos mejor o peor y qué gaps de contenido, reputación o autoridad están condicionando las respuestas.
El resultado ya no es una captura puntual. Es un mapa trazable de cómo los modelos generativos entienden, validan y recomiendan una marca dentro de su categoría.
Por qué importa el volumen
Una conversación aislada no diagnostica un mercado. Un prompt puede estar sesgado por la formulación, por la sesión, por el modelo, por el momento o por la configuración de búsqueda.
Para leer el mercado con fiabilidad hacen falta volumen y cobertura semántica. Eso implica generar un dataset amplio que cruce:
- customer personas;
- mercados;
- idiomas;
- líneas de producto;
- fases del funnel;
- intenciones;
- factores de compra;
- competidores;
- atributos de marca;
- prompts informativos, comparativos, transaccionales y escépticos.
Cuando ese volumen se combina con un algoritmo de completitud, el sistema puede detectar si el mapa de preguntas cubre suficientemente el espacio real de decisión. Esa es la diferencia entre hacer una prueba curiosa y construir una auditoría GEO con valor de negocio.
El punto crítico
En GEO, los datos sin precisión y sin volumen sirven de poco. Publicar mucho sin saber qué, cómo y para quién es disparar a ciegas.
La ventaja aparece cuando una marca sabe qué preguntas activan su categoría, qué fuentes alimentan las respuestas, qué atributos se le asignan, qué competidores ocupan su espacio y qué contenidos debe crear, corregir o activar para ser entendida, validada y recomendada por los modelos generativos.
Del diagnóstico al impacto en marca y negocio
Para lograr impacto real en marca y negocio, un estudio impecable no basta. El diagnóstico es la primera capa. Después hacen falta un plan de acción bien priorizado y herramientas para ejecutarlo con la escala, la precisión y la velocidad adecuadas.
El trabajo GEO debe convertir la lectura del mercado en decisiones operativas:
- qué fuentes activar primero;
- qué contenidos crear;
- qué contenidos corregir;
- qué gaps de conocimiento cerrar;
- qué atributos reforzar;
- qué mercados priorizar;
- qué customer personas atacar;
- qué competidores desplazar;
- qué prompts deben empezar a devolver otra respuesta.
La priorización no puede ser genérica. Hay que ordenar las fuentes según retorno esperado frente a esfuerzo e inversión. Una fuente puede tener mucha influencia semántica, pero exigir demasiado coste. Otra puede tener menos peso global y, aun así, ofrecer retorno inmediato si ayuda a validar un atributo de negocio, corregir sentimiento negativo o ganar presencia en un mercado concreto.
También necesitas un GEO técnico realista y con retorno medible. No todo se arregla publicando contenido. A veces el problema está en que la web no es fácil de leer para crawlers, no expone bien las entidades, estructura mal los datos, no usa el schema adecuado, oculta información crítica en assets poco accesibles o no ofrece rutas limpias para que los bots entiendan productos, servicios, expertos, ubicaciones, casos y claims.
La estrategia de contenidos debe priorizarse según los objetivos de marca. Hay dos áreas que conviene mirar con lupa:
- Gaps de conocimiento: lo que los LLMs no saben, no encuentran o interpretan mal sobre la marca.
- Benchmark competitivo: lo que la competencia ya está ocupando en prompts, fuentes, atributos, recomendaciones y mercados.
Y hay algo más: los contenidos no deberían crearse solo para gustar a personas o cubrir keywords. Deben encajar con el valor vectorial que buscan los bots de las IA cuando comparan una pregunta con los fragmentos disponibles. Eso exige contenidos alineados con prompts concretos, customer personas concretas y atributos de negocio concretos.
Por eso hacen falta herramientas que valoren esos contenidos antes de publicarlos, ayuden a crearlos con agilidad e indiquen a qué prompts están dirigidos. No basta con escribir un artículo sobre un tema. Hay que saber si ese artículo tiene probabilidad real de ser recuperado, entendido y usado por el modelo para construir una respuesta.
También hay que analizar el comportamiento conversacional. Una marca puede aparecer bien en el primer prompt y desaparecer cuando llega el segundo, el tercero o el cuarto prompt de la misma conversación. Ese punto importa porque muchos usuarios no deciden con una sola pregunta. Comparan, repreguntan, piden alternativas, filtran por precio, localización, confianza, uso concreto o dudas reputacionales.
La oportunidad es grande: aumentar conversión en un escenario donde el tráfico web orgánico cae de forma consistente y donde cada vez más decisiones empiezan, avanzan o se cierran dentro de interfaces generativas. GEO abre una disciplina nueva. No va solo de atraer visitas. Va de ser recomendado cuando el usuario ya está pidiendo ayuda para decidir.
Ser recomendado por modelos generativos implica competir por la atención y la confianza de más de mil millones de usuarios. Normal que esto exija herramientas nuevas, métodos nuevos y otra forma de conectar datos, contenidos, fuentes, tecnología y negocio.
Fuentes técnicas consultadas
- OpenAI Help Center: ChatGPT Search, proveedores externos de búsqueda y tratamiento de queries.
- OpenAI: Introducing ChatGPT Search, descripción de ChatGPT Search y proveedores externos.
- OpenAI Help Center: What are tokens and how to count them?, tokenización y variación por modelo/encoding.
- Google AI for Developers: Grounding with Google Search, conexión de Gemini con contenido web en tiempo real.
- Google AI for Developers: Understand and count tokens, tokenización y conteo de tokens en Gemini.
- Microsoft Learn: Grounding with Bing Search, flujo de queries generadas, resultados Bing y respuesta final del modelo.
- Microsoft Learn: Data, privacy, and security for web search in Microsoft 365 Copilot, queries generadas por Copilot y enviadas a Bing.
- Anthropic Docs: Web search tool, búsqueda web, resultados y citas en Claude.
- Perplexity Docs: Search API, resultados estructurados y diferencias con Sonar.
- Perplexity Docs: Sonar API, respuestas web-grounded con
search_resultsy citas.