Quan un usuari fa una pregunta que exigeix informació recent, un LLM no respon només des de la seva memòria interna. Pot activar sistemes de cerca, recuperar fragments del web, comparar-los semànticament, validar fonts i construir una resposta amb informació actualitzada.
La pregunta tècnica és aquesta: com passa un LLM d'un prompt escrit per una persona a una resposta fonamentada en documents, resultats de cerca i fragments recuperats en temps real?
Aquest article explica aquest flux. Ajuda a entendre per què ChatGPT, Gemini, Claude, Copilot o Perplexity poden respondre de manera diferent a la mateixa pregunta, per què no valoren igual les mateixes fonts i per què optimitzar per a LLMs exigeix mirar una capa més fina que el volum de continguts: quins fragments recuperen els models, per a quina intenció i dins de quin context.
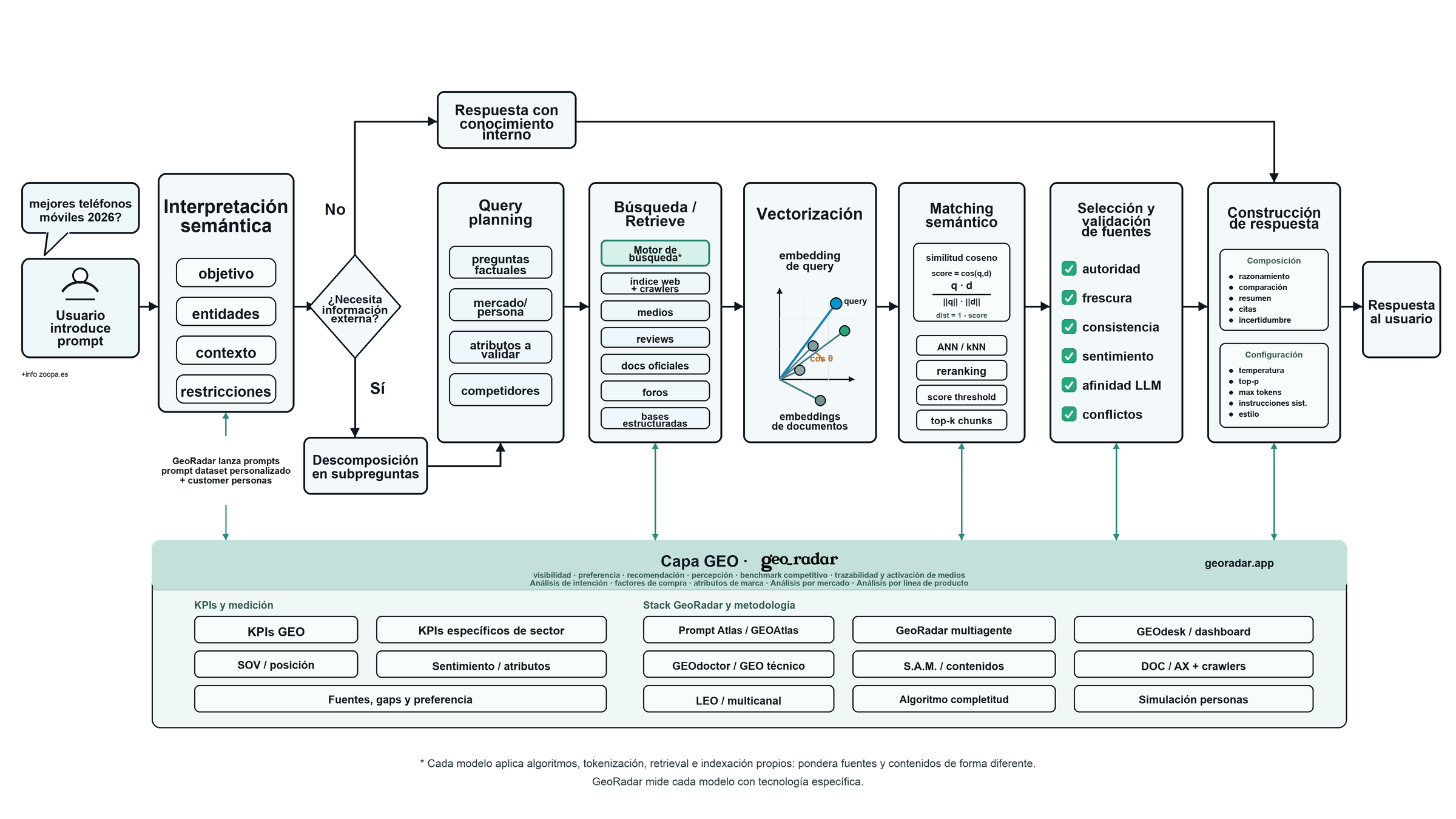
Diagrama en alta resolució: prompt, query planning, retrieve, vectorització, matching semàntic, validació de fonts i construcció de resposta.
Idea central
Un LLM rarament respon una pregunta complexa d'un sol cop. Primer interpreta què se li demana, detecta entitats, mira el context de la conversa i decideix si pot respondre amb el que ja sap o si necessita sortir a buscar informació.
Quan necessita dades actuals, entra en joc una altra maquinària: cerca, crawling, recuperació de fragments, comparació semàntica, validació de fonts i, al final, composició de la resposta.
Això és important per al GEO. Moltes respostes no surten només del coneixement preentrenat del model. Surten d'una barreja de raonament, recuperació, fonts trobades i criteris interns de composició. OpenAI documenta, per exemple, que ChatGPT Search pot decidir cercar al web segons allò que pregunti l'usuari, o permetre que l'usuari activi la cerca manualment.
En qualsevol categoria on importen actualitat, comparació o decisió, això canvia les regles. Una resposta sobre "millors bancs per a joves", "mòbils amb millor servei postvenda" o "marques de moda fiables a Espanya" pot quedar condicionada per fragments recuperats en mitjans, webs oficials, comparatives, fòrums, documentació tècnica, marketplaces o ressenyes d'usuaris.
Què passa quan l'usuari pregunta
Si algú escriu millors telèfons mòbils 2026, el model no està llegint només quatre paraules. Està llegint una intenció de compra. Hi ha comparació, actualitat, risc d'obsolescència, marques candidates, possibles rangs de preu i una expectativa bastant clara: l'usuari vol una recomanació, no una definició de què és un mòbil.
El sistema analitza:
- objectiu de resposta;
- entitats mencionades o implícites;
- context conversacional;
- mercat, idioma i data;
- restriccions explícites;
- criteris implícits de valor;
- factors de compra;
- atributs de marca rellevants;
- nivell d'actualitat requerit.
Aquest matís canvia tot el que ve després.
Decisió de cerca
El model, o la capa que l'orquestra, decideix si pot contestar amb coneixement intern o si necessita informació externa. En preguntes actuals, comparatives, transaccionals, reputacionals o molt vinculades a un mercat concret, és habitual que s'activi alguna forma de recuperació: cerca web, consulta a índexs, connectors o fonts estructurades.
La decisió pot dependre de:
- actualitat de la pregunta;
- presència de dates com
2026; - necessitat de preus, disponibilitat o novetats;
- risc d'informació obsoleta;
- necessitat de comparar marques;
- necessitat de citar o validar fonts;
- probabilitat que l'usuari esperi dades recents.
Si s'activa la cerca, el prompt original es converteix en un conjunt de subpreguntes: millors smartphones 2026, mòbils amb millor càmera, comparativa entre iPhone, Samsung i Xiaomi, opinions sobre bateria, disponibilitat a Espanya, problemes freqüents per model o marques recomanades per segment de preu.
En una consulta reputacional o comercial, aquesta descomposició pot incloure valoracions d'usuaris, queixes freqüents, ressenyes verificades, experiència en fòrums, comparatives amb competidors o senyals de confiança en plataformes especialitzades.
Motors de cerca i grounding per model
Hi ha una confusió habitual: pensar que si un LLM fa servir Bing, Google Search o un altre sistema de recuperació, llavors funciona com aquell cercador. No és així.
El cercador pot aportar URLs, snippets, documents o passatges. Després el model fa una altra cosa: reinterpreta, comprimeix, compara, descarta i converteix tot això en una resposta conversacional.
ChatGPT
OpenAI documenta que ChatGPT Search pot utilitzar proveïdors externs de cerca, inclòs Bing, juntament amb altres partners i continguts recuperats. Però ChatGPT no és Bing amb una interfície conversacional al damunt.
La cerca troba candidats. ChatGPT decideix què consultar, com reformular la pregunta, quins fragments utilitzar, com sintetitzar-los i com respondre segons les seves instruccions, el context de la conversa i les polítiques del producte.
Gemini
Google documenta Grounding with Google Search per a Gemini. Això significa que Gemini pot fonamentar una resposta amb resultats de Google Search. Però tampoc converteix Gemini en el cercador clàssic de Google.
Una pàgina pot posicionar bé a Google Search i, tot i així, no ser el fragment que Gemini decideix utilitzar en una resposta generativa. Per entrar a la resposta, la pàgina ha de ser recuperable, clara, estructurada i útil per a aquell objectiu conversacional concret.
Copilot
Microsoft Copilot s'inscriu de forma natural en l'ecosistema Bing i Microsoft. En entorns empresarials pot barrejar web, Microsoft Graph, documents corporatius, connectors i permisos de l'usuari.
Per al GEO això és important. El mateix contingut pot comportar-se de manera diferent en Copilot si s'avalua en mode web obert, dins d'un tenant corporatiu, amb Microsoft Graph disponible o amb connectors interns actius.
Claude
Anthropic documenta capacitats de web search per a Claude, amb recuperació d'informació actual i cites. A diferència de ChatGPT/Bing o Gemini/Google Search, les fonts públiques no permeten reduir Claude a un motor extern concret.
El que sí sabem és suficient per mesurar-lo per separat: Claude té el seu propi sistema de cerca, selecció de fonts, cites, raonament sobre documents i polítiques de resposta.
Perplexity
Perplexity es presenta com un sistema answer-first i search-native. Els seus productes Sonar i Search API treballen amb cerca web, recuperació i cites. L'experiència està pensada per respondre amb fonts visibles, però això no vol dir que seleccioni ni ponderi les mateixes fonts que Google, Bing, ChatGPT o Gemini.
Tokenització: per què cada LLM representa la informació de manera diferent
Abans de vectoritzar o generar una resposta, el model parteix el text en unitats internes: tokens. De vegades un token és una paraula. De vegades és mitja paraula, un signe, una seqüència freqüent o una peça sublèxica.
Cada família de models tokenitza a la seva manera. OpenAI utilitza tokenitzadors com els de la família tiktoken. Google ofereix eines de recompte de tokens per a Gemini. Anthropic documenta el seu propi recompte per a Claude. Cada sistema té vocabulari, límits de context i manera de tallar text.
Això pot afectar:
- com es consumeix la finestra de context;
- com es detecten entitats;
- com es preserven marques i noms de producte;
- com es comparen variants amb accents o sense;
- com es representen sigles, models, referències tècniques o preus;
- com es tallen documents llargs en chunks;
- quins fragments queden junts o separats.
Per al GEO, la conseqüència és clara: el mateix contingut no sempre "encaixa" igual en tots els LLMs. Un text pot ser transparent per a un model i menys llegible per a un altre si les entitats, els atributs, les dades estructurades o les frases de negoci no són prou explícites.
Vectorització de la pregunta i dels documents
Després arriba el pas que permet comparar preguntes i documents. La pregunta de l'usuari i els fragments recuperats es transformen en el mateix tipus de representació matemàtica.
La pregunta es converteix en un embedding:
pregunta de l'usuari -> vector qCada fragment recuperat també es converteix en un embedding:
fragment de document -> vector dTots dos vectors viuen en un espai semàntic comú. Gràcies a això es pot comparar significat, no només coincidència literal de paraules.
La comparació pot expressar-se així:
score = cos(q,d)
distància semàntica = 1 - scoreUn fragment que no repeteix literalment "millors mòbils 2026" pot ser molt útil si parla de rendiment, càmera, bateria, preu, disponibilitat local, satisfacció d'usuaris o problemes freqüents. El matching no depèn només de repetir la keyword. Depèn de la proximitat semàntica entre la necessitat de l'usuari i el contingut recuperat.
Matching semàntic i selecció de chunks
Un cop vectoritzats els chunks, el sistema busca els fragments més propers a la query mitjançant tècniques com ANN o kNN. Després pot aplicar:
- reranking;
- filtres de llindar;
- deduplicació;
- diversitat de fonts;
- filtres per data;
- filtres per idioma;
- validació de consistència;
- selecció de
top-k chunks.
El sistema intenta entregar al model un context compacte, útil i prou divers per construir una resposta.
El LLM no rep "tot internet". Rep una selecció limitada de fragments. Aquesta selecció condiciona la resposta final molt més del que sol semblar des de fora.
Com mesurar si un chunk és un bon match per a un prompt
Aquí convé introduir una capa d'avaluació que poques vegades s'explica en peces sobre GEO. Un crawler pot trobar una pàgina, però això no vol dir que el model la faci servir. La pregunta tècnica és més concreta: si el sistema divideix aquella pàgina en fragments, quins chunks encaixen realment amb el prompt?
Les mètriques que s'utilitzen per avaluar models d'embeddings donen una pista molt útil. No revelen l'algoritme intern de ChatGPT, Gemini, Claude, Copilot o Perplexity. Aquests sistemes són propietaris i combinen moltes senyals. Però sí que ajuden a mesurar, de manera reproduïble, si un embedding serveix per a retrieval, similitud semàntica, classificació temàtica i ranking de candidats.
| KPI | Què mesura | Lectura per a GEO |
|---|---|---|
XQuAD nDCG@10 |
Recuperació pregunta-context: es vectoritza una pregunta, s'ordenen contextos per similitud i s'avalua si els rellevants apareixen entre els 10 primers. | Mesura si el sistema recupera a dalt els chunks que realment podrien respondre el prompt. És la mètrica més propera al problema de retrieval. |
STS-ca Sp |
Similitud semàntica: compara la similitud de parelles de frases amb puntuacions humanes mitjançant correlació de Spearman. | Mesura si el mapa semàntic entén que dos textos poden respondre a la mateixa intenció encara que no comparteixin keywords. |
TeCla F1 |
Classificació temàtica en català: utilitza embeddings per separar classes temàtiques i mesura F1. | Indica si l'embedding conserva senyals útils per classificar intenció, sector, atribut, factor de compra o línia de producte. |
Dim |
Dimensionalitat del vector d'embedding. | Més dimensions poden capturar més matisos, però augmenten memòria, cost d'índex i latència. El millor model no sempre és el més gran. |
| Puntuació composta | Mitjana o combinació de diverses tasques. | Serveix per comparar models, però no substitueix una avaluació pròpia amb prompts, mercats, fonts i customer personas reals. |
nDCG@10 és especialment important perquè avalua ranking, no només semblança abstracta. En retrieval generatiu, aparèixer en posició 1, 2 o 3 no té el mateix valor que aparèixer en posició 37. El LLM treballa amb una finestra de context limitada; si el chunk correcte no entra en el top-k que s'entrega al model, a la pràctica no existeix per a aquella resposta.
STS-ca Sp cobreix un altre angle: la qualitat del mapa semàntic. Si l'usuari pregunta per "marques fiables per comprar mòbils el 2026", un bon sistema hauria d'acostar fragments que parlin de garantia, servei postvenda, satisfacció d'usuaris, problemes recurrents, disponibilitat local o relació qualitat-preu encara que no repeteixin literalment la frase del prompt.
TeCla F1 ajuda a entendre si l'embedding separa bé temes i categories. En GEO, aquesta lògica es pot traslladar a una taxonomia de negoci: intenció informativa, comparativa o transaccional; mercat; idioma; línia de producte; factor de compra; atribut de marca; competidor; etapa del funnel.
Una avaluació GEO madura no hauria de quedar-se en cos(q,d). Pot construir un score compost més proper a l'ús real:
prompt-source fit =
similitud semàntica
+ cobertura d'intenció
+ cobertura d'entitats
+ adequació a mercat i customer persona
+ frescor
+ especificitat del chunk
+ citabilitat de la font
+ evidència factual
+ diversitat davant d'altres chunksAquí canvia la lectura estratègica. Una pàgina amb molta autoritat pot fallar si no conté el fragment que el prompt necessita. Una font petita pot ser decisiva si inclou just el passatge que valida un atribut, resol un dubte o respon una comparació. Per això el treball GEO no s'hauria de quedar només en mesurar dominis. Cal mesurar fragments recuperables, la seva posició en el ranking semàntic i la seva capacitat real per sostenir una resposta.
Per això, quan estudiem com busquen els LLMs, convé guardar alguna cosa més que la URL citada: el chunk recuperat, el prompt que l'ha activat, la distància semàntica, la posició en el top-k, la intenció coberta, les entitats reconegudes i la funció que compleix dins de la resposta.
Protocol reproduïble per mesurar l'encaix prompt-chunk
Si volem que un estudi GEO aguanti una revisió seriosa, no n'hi ha prou amb dir "aquesta font ha aparegut" o "aquest model ha citat aquesta URL". Cal convertir l'observació en un experiment repetible. La unitat mínima ja no és el domini. És la relació entre prompt, chunk, model i resposta.
El que volem mesurar és molt concret: donat un conjunt de prompts, mercats, customer personas i competidors, quins fragments de quines fonts són recuperables, amb quin ranking, amb quin grau de rellevància i amb quin efecte en la resposta final?
El dataset mínim hauria de guardar aquests camps:
| Camp | Per què importa |
|---|---|
prompt_id, prompt_text, language, market |
Permeten repetir exactament la mateixa pregunta i segmentar-la per idioma i país. |
customer_persona, intent, product_line, purchase_factor |
Connecten el prompt amb una situació real de decisió: comparar, comprar, validar confiança, resoldre una objecció o buscar alternatives. |
brand, competitors, expected_attributes |
Fan visible quina marca, rivals i atributs haurien d'aparèixer si la resposta està ben orientada. |
source_url, source_type, publication_date, crawl_date |
Documenten d'on surt el contingut, quan s'ha capturat i quin tipus de font representa. |
chunk_id, chunk_text, chunk_hash |
Permeten auditar el fragment exacte, no només la pàgina. El hash ajuda a detectar canvis posteriors. |
model, search_surface, embedding_model |
Separen el LLM avaluat, la superfície de cerca i el model utilitzat per mesurar similitud. |
similarity_score, rank_position, relevance_label |
Registren proximitat semàntica, posició en el top-k i judici de rellevància. |
support_label, used_in_answer, citation_position |
Distingeixen si el chunk dona suport, contradiu o és insuficient per sostenir la resposta, i si ha acabat apareixent en la síntesi. |
La metodologia es pot executar en set passos:
- Congelar el prompt dataset. Abans de mesurar, es fixa el conjunt de prompts per mercat, idioma, customer persona, intenció, línia de producte, factor de compra i competidors. Si el dataset canvia durant l'estudi, la comparació perd valor.
- Capturar i fragmentar fonts. Es guarden HTML, text net, canonical URL, data de publicació, data de crawl, idioma, país i tipus de font. Després es divideixen els documents en chunks amb mida i solapament consistents.
- Indexar i comparar. Es creen embeddings dels prompts i dels chunks. Convé comparar com a mínim un baseline lèxic tipus BM25, un índex vectorial i una estratègia híbrida. Així es veu què apareix per coincidència literal i què apareix per proximitat semàntica.
- Rerankejar i etiquetar. Un segon pas reordena candidats. Després s'etiqueten amb una rúbrica:
0no rellevant,1tangencial,2útil,3central. També es marca si el fragment dona suport, contradiu o no conté evidència suficient. - Calcular mètriques. Per a cada prompt i segment es calculen
precision@k,recall@k,MRRinDCG@10. El tall per model, mercat, persona i intenció mostra on la marca és recuperable i on desapareix. - Vincular retrieval i resposta. No tots els chunks recuperats s'utilitzen. Cal mapar quins fragments acaben sostenint afirmacions concretes, quins només serveixen de context i quins són ignorats.
- Mesurar deriva. Repetir el mateix dataset en finestres temporals permet veure si una font guanya pes, si una marca perd presència conversacional o si un model canvia la manera de validar atributs.
En pseudocodi, el flux seria:
for prompt in prompt_dataset:
q = embed(prompt.text)
candidates = retrieve_top_k(q, chunk_index, k=50)
reranked = rerank(prompt, candidates)
labels = judge_relevance(prompt, reranked)
metrics = evaluate(labels, k=[3, 5, 10])
answer = run_llm_with_retrieval(prompt)
claims = map_answer_claims_to_chunks(answer, reranked)
store(prompt, candidates, labels, metrics, answer, claims)Un chunk és un bon match quan apareix en el top-k rellevant, rep una etiqueta igual o superior a 2, cobreix la intenció del prompt, conté entitats explícites, encaixa amb mercat i customer persona, ofereix evidència verificable i no contradiu fonts més sòlides. Una font és estratègicament valuosa quan apareix de manera recurrent en variants de prompts, persones, models o mercats i millora la resposta final.
La discrepància entre models no molesta; informa. Si un embedding, un LLM o una superfície de cerca recupera un fragment i una altra no, aquesta diferència revela com cada sistema representa la informació, tokenitza els textos, pondera senyals i empaqueta context. Aquí hi ha una part essencial del treball GEO: saber què diu una IA, sí, però també per què ho ha pogut dir i quin contingut l'ha portat fins aquí.
Com fan el matching semàntic els diferents LLMs
No existeix una única manera de fer "matching semàntic de LLMs". Cada sistema barreja peces diferents: cerca lèxica, cerca vectorial, embeddings, senyals de frescor, rerankers neuronals, classificadors d'intenció, filtres de seguretat, polítiques de producte i preferències de citabilitat.
Una arquitectura típica pot incloure:
-
Retrieval lèxic
Coincidència per termes, entitats, noms de marca, dates, URLs, títols o expressions exactes. -
Retrieval semàntic
Comparació entre embeddings de la query i embeddings de chunks. Troba contingut que respon al significat encara que faci servir altres paraules. -
Hybrid retrieval
Barreja cerca lèxica i vectorial. Aguanta millor dos errors habituals: perdre documents exactes perquè no semblen prou "semàntics", o recuperar documents semblants en significat però factualment incorrectes. -
Reranking
Un segon model reordena candidats segons la utilitat esperada per a la resposta. -
Context packing
El sistema decideix quins chunks caben dins de la finestra de context. -
Answer planning
El LLM decideix com utilitzar aquells fragments: llista, comparació, resum, advertiment, recomanació, taula o resposta directa.
Per què no se seleccionen dominis només per autoritat
En SEO clàssic solem mirar autoritat de domini, keywords, backlinks i ranking general. En retrieval generatiu això es queda curt.
Un domini molt fort pot no aportar el fragment adequat per a una pregunta concreta. I una font més petita pot acabar sent decisiva si conté just el passatge que encaixa amb l'objectiu de l'usuari.
El sistema pot valorar:
- match semàntic: si el chunk respon exactament a l'objectiu del prompt;
- frescor: si la informació està actualitzada;
- proximitat geogràfica: si la font és rellevant per a Espanya, Europa, LATAM o un altre mercat;
- idioma i localització: si el contingut coincideix amb l'idioma real de l'usuari;
- adequació a la customer persona: comprador tècnic, usuari familiar, CMO, pacient, estudiant, viatger;
- factors de compra: preu, confiança, garantia, disponibilitat, reputació;
- atributs de marca: innovació, sostenibilitat, fiabilitat, luxe, seguretat, servei;
- tipus de font: mitjà, plataforma de reviews, web oficial, fòrum, marketplace, documentació tècnica;
- consistència: si diverses fonts independents confirmen el mateix punt;
- sentiment: si la font reforça o deteriora la percepció de marca;
- crawlability: si el contingut és fàcil de llegir, extreure, indexar i citar;
- dades estructurades: schema, taules, FAQs, metadades, dates, autoria i entitats clares.
La conseqüència és incòmoda per a moltes estratègies heretades: en GEO no guanya necessàriament el domini més gran. Guanya el contingut que el sistema pot trobar, entendre, comparar i utilitzar per resoldre una pregunta concreta.
Fonts UGC dins del flux GEO
Les capes d'UGC tenen un paper particular dins d'aquest sistema. No solen ser l'única font d'una resposta, però poden funcionar com a senyal de validació quan l'usuari pregunta per confiança, qualitat de servei, satisfacció, problemes freqüents o comparació entre marques.
Per a un LLM, una font d'experiència real d'usuaris pot aportar:
- evidència d'experiència real;
- llenguatge natural sobre problemes i beneficis;
- sentiment agregat;
- senyals de recurrència;
- vocabulari de customer persona;
- atributs de marca que no apareixen a la web oficial;
- contrast davant del claim comercial de la marca.
Això explica per què les reviews importen en GEO encara que no sempre siguin la font més citada. De vegades el seu valor no és aparèixer com a enllaç principal, sinó confirmar o tensionar el que altres fonts diuen sobre la marca.
Validació de fonts
Abans de generar la resposta final, el sistema pot valorar autoritat contextual, frescor, consistència, conflictes entre fonts, sentiment, afinitat amb la pregunta i utilitat real per a l'usuari.
També pot detectar si hi ha fonts contradictòries. Per exemple:
- una web oficial afirma un benefici;
- una plataforma de reviews mostra queixes recurrents;
- un mitjà sectorial valida un avantatge;
- un fòrum introdueix sentiment negatiu;
- una comparativa local afavoreix un competidor.
La resposta final es construeix a partir d'aquesta tensió entre fonts. Per això una marca no hauria d'obsessionar-se només amb "aparèixer". La pregunta bona és més concreta: quins fragments apareixen, com els representa cada LLM, amb quin sentiment, per a quina customer persona són rellevants i en quin context estan disponibles per als sistemes generatius.
Construcció de resposta
Un cop seleccionats els fragments rellevants, el LLM elabora la resposta combinant:
- el prompt original de l'usuari;
- la interpretació semàntica de la tasca;
- els chunks recuperats;
- les instruccions del sistema;
- polítiques de seguretat;
- paràmetres de generació;
- estil esperat;
- límit de tokens;
- temperatura;
- top-p.
La resposta no és una còpia de les fonts. És una síntesi generativa. El model resumeix, compara, ordena, suavitza incerteses i decideix què omet i què destaca. Per això el resultat final depèn tant dels documents recuperats com de la forma en què el model interpreta la seva rellevància.
On entren GeoRadar, S.A.M. i LEO
Aquí és on GeoRadar deixa de ser una eina de reporting i es converteix en una eina de recerca.
En aquesta capa metodològica, el stack té un paper concret. GeoRadar observa el comportament dels models: prompts, respostes, fonts, atributs i competència. S.A.M. ajuda a comprovar si un contingut està semànticament alineat amb els prompts i atributs que volem cobrir. LEO porta aquesta lectura a una lògica d'activació multicanal. L'objectiu és molt concret: fer traçable quina pregunta activa quina font, quin fragment sosté quina resposta i quin buit de contingut encara cal cobrir.
Si llancem milers de prompts personalitzats, creuats per customer persona, mercat, línia de producte, intenció, factors de compra i competidors, i a més utilitzem un sistema que comprova que aquestes preguntes cobreixen l'espai real del negoci, podem estimular la IA d'una manera molt semblant a com ho farien usuaris reals en sessions ordinàries.
Després guardem i analitzem aquestes converses. Així es veu quines fonts recuperen els LLMs una vegada i una altra, com de visibles i recomanats som, quins atributs associen a la nostra marca, amb quin sentiment parlen de nosaltres, com ens comparen amb la competència, en quins mercats apareixem millor o pitjor i quins gaps de contingut, reputació o autoritat estan condicionant les respostes.
El resultat ja no és una captura puntual. És un mapa traçable de com els models generatius entenen, validen i recomanen una marca dins de la seva categoria.
Per què importa el volum
Una conversa aïllada no diagnostica un mercat. Un prompt pot estar esbiaixat per la formulació, la sessió, el model, el moment o la configuració de cerca.
Per llegir el mercat amb fiabilitat calen volum i cobertura semàntica. Això implica generar un dataset ampli que creui:
- customer personas;
- mercats;
- idiomes;
- línies de producte;
- fases del funnel;
- intencions;
- factors de compra;
- competidors;
- atributs de marca;
- prompts informatius, comparatius, transaccionals i escèptics.
Quan aquest volum es combina amb un algoritme de completitud, el sistema pot detectar si el mapa de preguntes cobreix prou bé l'espai real de decisió. Aquesta és la diferència entre fer una prova curiosa i construir una auditoria GEO amb valor de negoci.
El punt crític
En GEO, les dades sense precisió i sense volum serveixen de poc. Publicar molt sense saber què, com i per a qui és disparar a cegues.
L'avantatge apareix quan una marca sap quines preguntes activen la seva categoria, quines fonts alimenten les respostes, quins atributs se li assignen, quins competidors ocupen el seu espai i quins continguts ha de crear, corregir o activar per ser entesa, validada i recomanada pels models generatius.
Per aconseguir impacte real en marca i negoci, un estudi impecable es queda a mig camí si no baixa a l'acció. El diagnòstic és la primera capa. Després calen un pla ben prioritzat i eines per executar-lo amb l'escala, la precisió i la velocitat adequades.
Fonts tècniques consultades
- OpenAI Help Center: ChatGPT Search, proveïdors externs de cerca i tractament de queries.
- OpenAI: Introducing ChatGPT Search, descripció de ChatGPT Search i proveïdors externs.
- OpenAI Help Center: What are tokens and how to count them?, tokenització i variació per model/encoding.
- Google AI for Developers: Grounding with Google Search, connexió de Gemini amb contingut web en temps real.
- Google AI for Developers: Understand and count tokens, tokenització i recompte de tokens a Gemini.
- Microsoft Learn: Grounding with Bing Search, flux de queries generades, resultats Bing i resposta final del model.
- Microsoft Learn: Data, privacy, and security for web search in Microsoft 365 Copilot, queries generades per Copilot i enviades a Bing.
- Anthropic Docs: Web search tool, cerca web, resultats i cites a Claude.
- Perplexity Docs: Search API, resultats estructurats i diferències amb Sonar.
- Perplexity Docs: Sonar API, respostes web-grounded amb
search_resultsi cites. - Lewis et al.: Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks, paper base sobre RAG.
- Karpukhin et al.: Dense Passage Retrieval for Open-Domain Question Answering, recuperació densa pregunta-passatge.
- Thakur et al.: BEIR: A Heterogeneous Benchmark for Zero-shot Evaluation of Information Retrieval Models, benchmark per a recuperació d'informació.
- Reimers i Gurevych: Sentence-BERT, embeddings de frases mitjançant xarxes siameses.
- Stanford NLP: Introduction to Information Retrieval, fonaments de ranking, recuperació lèxica i models clàssics.
- Johnson, Douze i Jégou: Billion-scale similarity search with GPUs, arquitectura FAISS per a cerca vectorial a gran escala.
- Malkov i Yashunin: Efficient and robust approximate nearest neighbor search using Hierarchical Navigable Small World graphs, base de HNSW per a ANN.
- Khattab i Zaharia: ColBERT, late interaction per a ranking eficient i precís.
- MTEB: Massive Text Embedding Benchmark, benchmark d'embeddings en múltiples tasques i idiomes.
- Google DeepMind: XQuAD, dataset multilingüe de question answering amb 240 paràgrafs i 1190 parelles pregunta-resposta.
- scikit-learn: nDCG score, mètrica de ranking amb descompte logarítmic per posició.
- SciPy: Spearman rank correlation, correlació no paramètrica entre rankings.
- scikit-learn: F1 score, mitjana harmònica de precisió i recall.
- Projecte AINA / CLUB: benchmark català CLUB, tasques de classificació, STS i QA en català.
- Projecte AINA: TeCla, corpus català de classificació temàtica.