A finales de diciembre de 2025 me topé, como medio GitHub, con un pequeño proyecto open source llamado pxpipe, trending aquella semana con una afirmación que suena a error de facturación: la misma sesión de Claude Code que costaba 42,21 dólares como texto plano costó 4,51 cuando las partes voluminosas de la petición se convirtieron en imágenes PNG antes de salir de la máquina.
Mismo modelo, misma tarea, mismas respuestas. La única diferencia es que el modelo leyó la mayor parte de su contexto con los ojos en lugar de con el tokenizador.
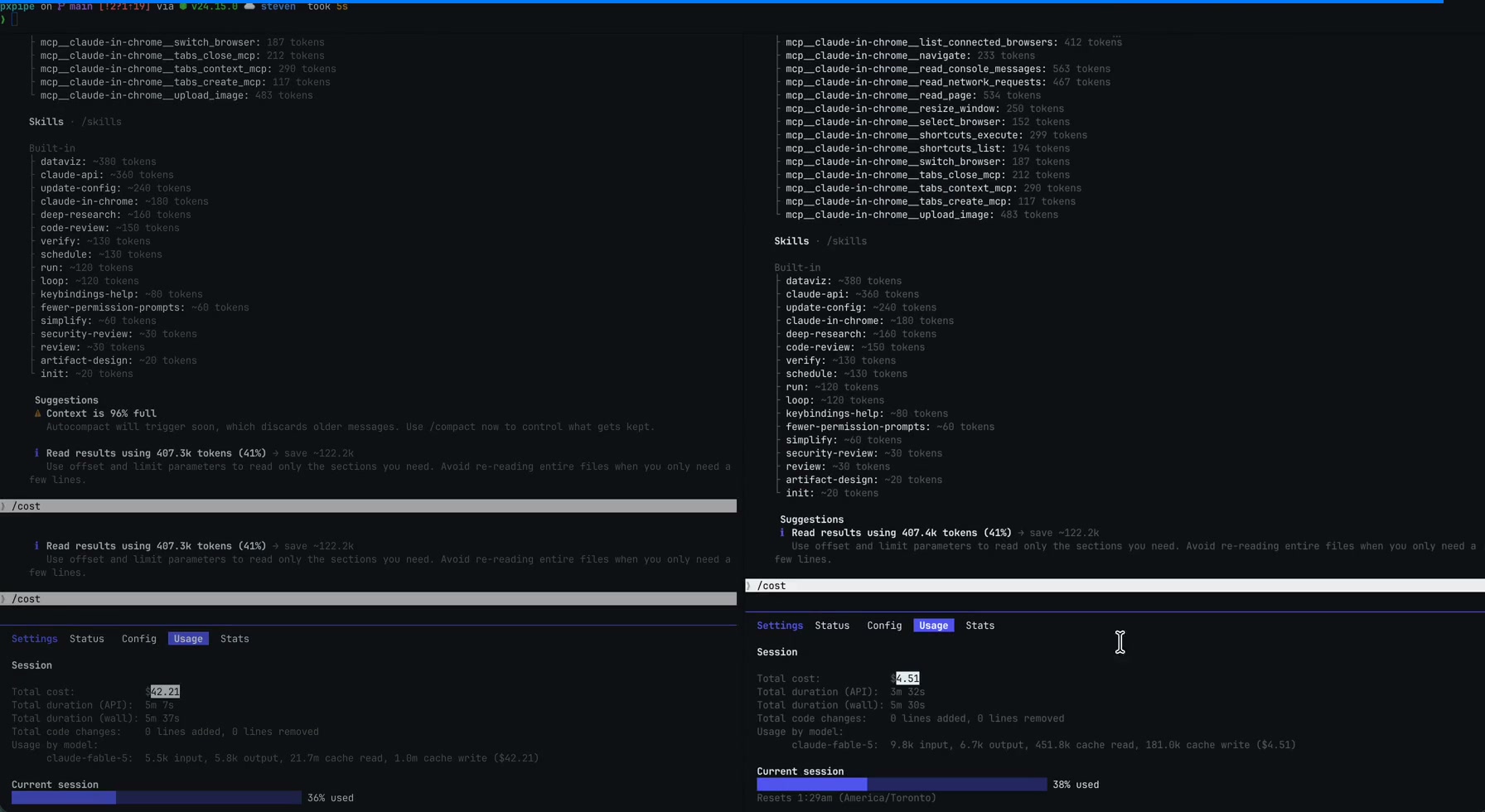
El A/B que corrió por todas partes: la misma sesión, 42,21 dólares como texto y 4,51 con el contexto imaginado. Fuente: repo de pxpipe (MIT).
Merece la pena desmontar ese número, porque el mecanismo que hay detrás es más grande que una herramienta. Explica una palanca de coste real para cualquiera que opere agentes o pipelines de contexto largo. Y conecta con una segunda pregunta que casi nadie ha ligado todavía a la primera: cuando un sistema de IA visita tu web en tiempo real, ¿qué ve exactamente? La respuesta, cada vez más, pasa por el mismo canal de visión.
El mecanismo: las imágenes se cobran por píxeles, no por caracteres
Todos los modelos multimodales ponen precio a una imagen según sus dimensiones. Una imagen de 1000x1000 píxeles cuesta los mismos tokens contenga un vacío blanco o 5.000 palabras de documentación densa. El contador de tokens cuenta píxeles. Le da igual lo que haya pintado encima.
El texto, en cambio, se cobra carácter a carácter. En tráfico real de Claude Code, el contenido denso tipo código, JSON y logs sale a aproximadamente un carácter por token de texto. Ese mismo contenido renderizado en una imagen bien compactada sale a unos 3,1 caracteres por token de imagen.
Ese hueco es todo el truco. El ejemplo canónico de la documentación de pxpipe: un bloque de unos 48.000 caracteres (system prompt más documentación de herramientas) cuesta unos 25.000 tokens como texto. Renderizado como un PNG denso, cuesta unos 2.700 tokens de imagen. La misma información, un 89 % menos de tokens en ese bloque.

Lo que recibe el modelo: 48.000 caracteres con el espacio en blanco minificado, recolocados en filas completas, con marcas ↵ donde estaban los saltos de línea originales. Fuente: repo de pxpipe (MIT).
Para que un codificador visual pueda leer esa página, el texto pasa por tres preparaciones. Se elimina el espacio en blanco redundante. Las líneas se redistribuyen hasta llenar filas completas de la imagen, con columnas que envuelven a unos 1.928 píxeles de ancho. Y se insertan pequeñas marcas ↵ donde estaban los saltos de línea originales, para que la estructura sobreviva a la compactación. Una página densa empaqueta unos 92.000 caracteres.
Por qué los píxeles ganan a las palabras llevando palabras
Lo contraintuitivo no es la facturación. Es que el modelo de verdad puede leer esto.
Sean Goedecke escribió un buen análisis de por qué las cuentas salen. Un token de texto es una elección discreta: una opción entre un vocabulario de unas 50.000 entradas, que después se mapea a un vector de embedding. Un token de imagen no tiene esa restricción. Puede ocupar cualquier punto del espacio de embeddings, y eso lo hace mucho más expresivo por unidad. La investigación de DeepSeek le pone número: de un solo token de imagen se pueden recuperar unos 10 tokens de texto con precisión casi perfecta.
La idea no es nueva, y eso es parte de lo interesante del momento. La vi en un post, la probé y la he seguido usando desde entonces. La gente lleva años pegando capturas en modelos multimodales, y la objeción de siempre era la misma: los codificadores visuales no eran lo bastante fiables leyendo letra pequeña y densa, así que nadie en su sano juicio enrutaba contexto de producción por ahí. Lo que cambió entre 2024 y ahora son los codificadores. Cuando DeepSeek publicó sus resultados de compresión óptica y pxpipe publicó sus evals, la conversación pasó de "esto ni siquiera funcionaría" a "esta es la ratio exacta donde deja de funcionar". Esa es la diferencia entre un truco de fiesta y una opción de ingeniería.
Así cuentan hoy los tokens de imagen los principales proveedores:
| Proveedor | Cómo se cobra una imagen | Una imagen de 1000x1000 px |
|---|---|---|
| Anthropic (Claude) | Patches de 28x28 píxeles, un token visual cada uno: ⌈ancho/28⌉ x ⌈alto/28⌉ | 1.296 tokens |
| OpenAI (detail high) | 85 tokens base + 170 por tile de 512x512 tras el reescalado | 765 tokens |
| Google (Gemini) | 258 tokens fijos si ≤384 px, si no 258 por tile de 768x768 | 1.032 tokens |
En los modelos actuales de Claude (Fable 5, Opus 4.7 y 4.8), una imagen tiene un tope de 4.784 tokens visuales con un borde largo de hasta 2.576 píxeles. El ancho de render de pxpipe, 1.928 píxeles, cabe con margen bajo ese techo. Nada de esto es casualidad.
La letra pequeña de cada proveedor
Los detalles importan más que la fórmula de titular, porque cada proveedor esconde compromisos distintos en ellos.
Los modelos antiguos de Anthropic limitaban las imágenes a 1.568 píxeles de borde largo y 1.568 tokens visuales. Todo lo que llegara más grande se reducía antes de procesarse, lo que ponía un techo silencioso al coste y a la resolución a la vez. Todavía encontrarás en textos antiguos la aproximación "tokens igual a ancho por alto entre 750". La matemática de patches la sustituyó: 28 por 28 píxeles por token visual, redondeando hacia arriba en cada eje. Para una imagen de 1000x1000 las dos fórmulas caen a menos del 3 % una de otra, y por eso la regla vieja sobrevivió tanto tiempo.
OpenAI trabaja en dos pasos: la imagen se escala para caber en un cuadrado de 2048 píxeles, después su lado más corto se lleva a 768 píxeles, y solo entonces se aplica el troceado en tiles de 512. El modo "low detail" se salta todo eso por 85 tokens fijos, que para leer texto no sirve de nada pero para "es esto un gato" va sobrado.
El enfoque de Google es el más directo: cualquier cosa de hasta 384 píxeles por ambos lados son 258 tokens, punto. A partir de ahí, tiles de 768 píxeles a 258 cada uno.
De aquí salen tres consecuencias. Primera: el tamaño óptimo de render depende del proveedor, así que un pipeline afinado para Claude desperdicia dinero en Gemini. Segunda: redimensionar antes de subir es una decisión tuya, y tomarla conscientemente gana a dejar que la API reduzca por ti. Tercera: los topes por imagen hacen que los documentos muy largos prefieran varias páginas de densidad media antes que una sola gigante. pxpipe empaqueta unos 92.000 caracteres por página y simplemente emite un array de PNGs cuando el contenido desborda.
![]()
La idea en una imagen: contexto idéntico, 90 tokens como texto, 50 como imagen. Fuente: "Text or Pixels? It Takes Half" (arXiv 2510.18279), CC BY 4.0.
Qué dice la investigación
Dos papers de octubre de 2025 pusieron esto sobre base sólida.
"Text or Pixels? It Takes Half" probó la idea de forma sistemática en GPT-4.1-mini y Qwen2.5-VL-72B. El montaje era cuidadoso: texto compuesto con LaTeX a 300 DPI, tamaño de fuente adaptativo buscando un fill ratio de 0,8, resoluciones de 600x800 a 750x1000 píxeles. Renderizar texto largo como imagen logró una compresión de aproximadamente 2:1 (entre un 38 % y un 58 % menos tokens de decoder) manteniendo la precisión a menos de 3 puntos del baseline solo-texto. En retrieval tipo aguja en el pajar, el brazo imaginado puntuó entre el 97 % y el 99 %; en resumen sobre CNN/DailyMail batió a baselines de compresión dedicados como LLMLingua-2 a ratios equivalentes. Y hubo un extra que nadie esperaba: en Qwen2.5-VL-72B, la secuencia de decoder más corta hizo la inferencia entre un 25 % y un 45 % más rápida de punta a punta. Más barato y más rápido, con el mismo truco.
DeepSeek-OCR, publicado el mismo mes, fue más allá y cartografió los límites. Su trabajo de "compresión óptica de contextos" muestra que mientras la ratio entre tokens de texto y tokens de visión se mantiene por debajo de 10x, la precisión de decodificación aguanta en el 97 %. Fuerza hasta 20x y la precisión cae a alrededor del 60 %. La curva entre esos dos puntos es la lista de precios de toda esta técnica.
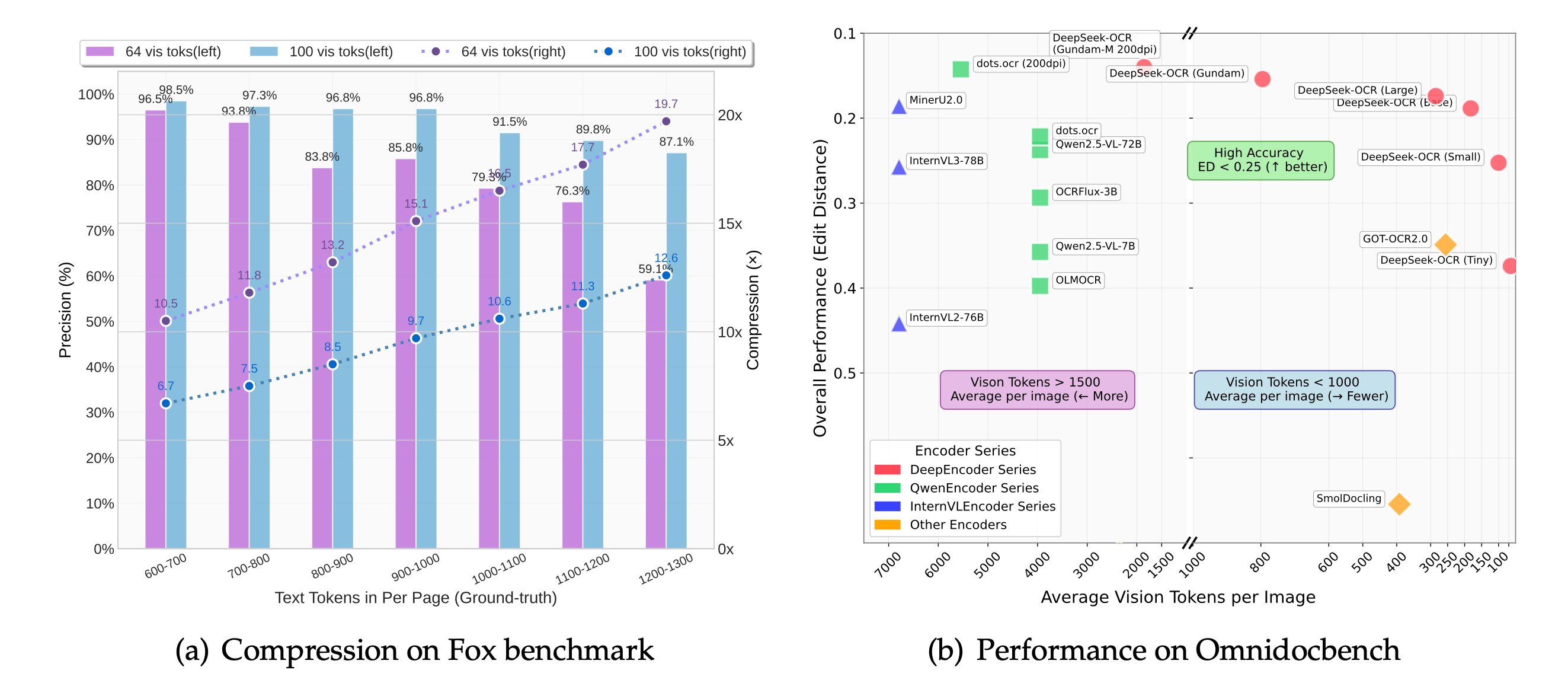
La frontera de la técnica: la precisión aguanta cerca del 97 % por debajo de compresión 10x, y después se degrada. En OmniDocBench, 100 tokens de visión por página baten a sistemas que gastan 256, y menos de 800 baten a sistemas que gastan más de 6.000. Fuente: DeepSeek-OCR (arXiv 2510.18234), CC BY 4.0.
Los números de eficiencia cuesta ignorarlos. DeepSeek-OCR lee una página de documento con 100 tokens de visión y bate a GOT-OCR2.0, que gasta 256 por página. Con menos de 800 supera a MinerU2.0, que promedia más de 6.000. En producción, DeepSeek usa esto para generar datos de entrenamiento para LLMs a más de 200.000 páginas al día en una sola A100-40G.
La sección de discusión del paper contiene la idea más de ciencia ficción de todo este espacio: la memoria óptica. Guardar el historial antiguo de una conversación como imágenes a resolución cada vez menor, de forma que el contexto lejano literalmente se difumina como se difuminan los recuerdos humanos. Volvemos a ella al final.
Dentro de un pipeline de producción
pxpipe es la implementación más instructiva de leer porque publica sus evals y sus casos de fallo. Funciona como un proxy local entre tu cliente y la API de Claude. Las peticiones pasan byte a byte idénticas salvo tres categorías de contenido, cada una detrás de una puerta de rentabilidad: resultados de herramientas por encima de unos 6.000 caracteres de contenido denso, turnos antiguos de conversación por detrás de la cola viva, y el bloque estático de system prompt más documentación de herramientas.
Dos reglas de diseño importan más que el resto. Los turnos recientes siempre se quedan como texto. Y el prefijo estático se conserva intacto, porque romper el prompt caching se comería el ahorro.
Los resultados medidos, de las propias tablas de benchmark del proyecto:
| Test | Baseline texto | Con contexto imaginado |
|---|---|---|
| Aritmética nueva, Claude Fable 5 (n=100) | 100/100 | 100/100, con un 38 % menos tokens |
| Gist recall A/B (n=98) | 98/98 | 98/98 |
| State tracking (n=18) | 18/18 | 18/18 |
| SWE-bench Lite (n=10) | 10/10 | 10/10, peticiones un 65 % más pequeñas |
| Recall de hex de 12 caracteres, Opus (n=15) | 15/15 | 0/15 |
Mira otra vez esa última fila. Volvemos a ella enseguida.
En SWE-bench Pro, el benchmark agéntico difícil, el brazo imaginado resolvió 14 de 19 tareas contra 15 de 19 del texto plano, con peticiones un 60 % más pequeñas y 18 de 19 ejecuciones coincidiendo en el veredicto final. Esa es la forma honesta del compromiso en trabajo difícil: un pequeño impuesto de precisión en los problemas más duros, comprado a más de la mitad de precio.
De punta a punta, sobre un snapshot de 13.709 peticiones reales, la factura bajó un 59 %, de 100 dólares a unos 41. Las trazas donde la compresión aplicaba con fuerza salieron entre un 70 % y un 74 % más baratas.
Vienen dos costes operativos con el paquete. Codificar PNGs añade latencia en peticiones grandes, y se nota cuando tu pipeline es sensible a la latencia y no al coste. Y la técnica está batallada en contenido ASCII y Latin-1; el CJK funciona pero el proyecto lo trata de forma conservadora, con un empaquetado menos agresivo. Si tu contexto es mayoritariamente chino o japonés, tu ratio de compresión será peor que los números de titular.
Cuándo imaginar tu contexto suma, y cuándo resta
Cualquier artículo sobre esta técnica que solo cite el ahorro te está haciendo un flaco favor. El método es con pérdida, y falla de una manera concreta y fea.
Lo primero que se rompe es el recall exacto de cadenas cortas. En el test de pxpipe, Opus recordó cadenas hex de 12 caracteres desde contenido imaginado 0 veces de 15. El más reciente Fable 5 llegó a 13 de 15. Y los fallos no son errores que puedas cazar: el modelo confabula un valor plausible con total confianza en lugar de decir que no lo puede leer. El proyecto documenta un caso real de un nombre recordado mal, con seguridad absoluta, desde historial imaginado.
También depende del modelo. La técnica funciona porque los codificadores visuales frontera actuales (Claude Fable 5, GPT 5.6) leen texto denso casi perfecto. Opus 4.7 y 4.8 lo malinterpretan alrededor de un 7 % de las veces, y por eso pxpipe los deja en opt-in. Un modelo sin un buen codificador lector convierte tu contexto comprimido en ruido.
La regla práctica honesta: imaginar suma cuando el contenido es contexto a granel para razonar (código, documentación, logs, turnos antiguos de conversación). Resta cuando cualquier byte importa exactamente. Hashes, claves de API, IDs, teléfonos y todo lo que vayas a necesitar citar de vuelta literal debe quedarse como texto, siempre.
Un aviso más, y es el estratégico: el arbitraje se mueve. Cuando Anthropic publicó Opus 4.7, la resolución nativa máxima de imagen saltó de 1.568 a 2.576 píxeles de borde largo, y las capturas típicas pasaron de unos 1.558 tokens a 4.739. La misma imagen, el triple de coste, en una release. La lección no es "usa el truco". La lección es: entiende la economía por píxel de tu proveedor y mídela, porque cambia sin preguntarte.
Pruébalo en diez minutos
Si usas Claude Code, el experimento cuesta dos comandos:
npx pxpipe-proxy
ANTHROPIC_BASE_URL=http://127.0.0.1:47821 claudeUn dashboard en 127.0.0.1:47821 enseña cada conversión y los tokens ahorrados. El proxy solo toca modelos de su allowlist; todo lo demás pasa byte a byte idéntico, y puedes apagarlo entero con PXPIPE_MODELS=off.
Para tus propios pipelines, la misma maquinaria está disponible como librería:
import { renderTextToPngs, transformAnthropicMessages } from "pxpipe";
const imgs = await renderTextToPngs(bigToolResultText);
const { body, applied } = await transformAnthropicMessages({
body: requestBytes,
model: "claude-fable-5",
});Antes de fiarte de ningún número, mide tu propio baseline. El endpoint count_tokens de Anthropic es gratuito, y comparar peticiones imaginadas contra planas sobre tu tráfico real te lleva una tarde. Mi checklist para quien adopte esto:
- Filtra por densidad. La prosa comprime mal; el código, el JSON y los logs comprimen bien.
- Mantén la cola viva de la conversación como texto, siempre.
- Deja fuera del camino imaginado todo lo byte-exacto (hashes, claves, IDs, importes).
- Vuelve a medir con cada release de modelo. El repricing de Opus 4.7 triplicó el coste de las imágenes de un día para otro.
- Registra qué se comprimió. Cuando aparezca una confabulación, querrás saber qué estaba leyendo el modelo.
La parte que casi nadie conecta: así leen también tu web las IAs
Todo lo anterior trata el texto-como-imagen como un truco de coste que aplicas a tus propias peticiones. Ahora dale la vuelta a la dirección. Cuando ChatGPT, Claude, Perplexity o un navegador agéntico visitan una página de tu web en tiempo real, ¿qué ven?
Resulta que tu web no tiene un lector de IA. Tiene tres, y no se ponen de acuerdo.
Tu web ya tiene tres lectores de IA: el crawler, Google y el agente. Y ninguno ve la misma página.

La misma página, tres lecturas: HTML crudo para los crawlers, página renderizada para Google, píxeles para los agentes.
Lector uno: los crawlers. Cada empresa de IA lanza tres familias de bots contra tu web. Un crawler de entrenamiento (GPTBot, ClaudeBot) recolecta contenido para modelos futuros. Un bot de índice de búsqueda (OAI-SearchBot, Claude-SearchBot) alimenta la capa de búsqueda del asistente. Y un fetcher disparado por el usuario (ChatGPT-User, Perplexity-User) golpea tu página en vivo, en los segundos entre la pregunta de un usuario y la respuesta. Ese último es el "tiempo real" de las respuestas de IA en tiempo real.
A mediados de 2026, ninguno ejecuta JavaScript. Ninguno, en ninguna de las tres familias. El análisis de tráfico de producción de Vercel encontró que GPTBot descarga ficheros JavaScript alrededor del 11,5 % de las veces (ClaudeBot el 23,8 %) y nunca los ejecuta. Recogen el HTML crudo, extraen lo que hay y siguen. Sin segunda pasada, sin cola de renderizado. Si tu contenido solo existe en el DOM después del renderizado en cliente, para estos sistemas no existe.
Lector dos: Google, la excepción. Gemini y AI Overviews heredan la infraestructura de Googlebot, y Googlebot sí renderiza JavaScript. Martin Splitt, de Google, lo ha confirmado. La consecuencia práctica es rara y muy real: la misma página puede ser completamente visible para las superficies de IA de Google e invisible para ChatGPT, Claude y Perplexity al mismo tiempo. Si tu marca aparece en AI Overviews pero nunca en las respuestas de ChatGPT, revisa cuánto de tu contenido depende de JavaScript antes de culpar al modelo.
Lector tres: los agentes. Los navegadores agénticos como Atlas de OpenAI (movido por su Computer-Using Agent) y Comet de Perplexity leen la página completamente renderizada, con una mezcla de snapshots del árbol de accesibilidad, parsing del DOM y capturas enviadas a un modelo de visión. Aquí es donde la primera mitad de este artículo vuelve a aparecer: los agentes están leyendo páginas web por el mismo canal de visión, con la misma economía y la misma curva de degradación. Los números de DeepSeek aplican también aquí. Una página limpia y bien estructurada se lee al 97 %. Una densa y desordenada resbala hacia el extremo del 60 %, y el agente rellena los huecos con suposiciones seguras de sí mismas.
Hay un cuarto patrón que conviene conocer en el lado del retrieval. ColPali (ICLR 2025) demostró que para búsqueda documental, saltarse el OCR por completo y hacer embedding directo de las imágenes de página bate al pipeline clásico de extraer y trocear: 0,81 contra 0,66 de NDCG@5, indexando páginas en 0,39 segundos en lugar de 7,22. El layout, las tablas y las figuras que la extracción de texto destruye resultan llevar significado recuperable. La estructura visual es información.
Qué significa esto si publicas contenido
Si tienes una web que te gustaría que los sistemas de IA leyeran bien, la división en tres lectores se traduce en trabajo comprobable:
- Sirve la sustancia en HTML crudo. Renderiza en servidor o prerenderiza todo lo que quieras que vean crawlers y fetchers en vivo: precios, especificaciones, FAQs, comparativas. El test cuesta un comando: haz
curla tu página y busca tus datos clave en la respuesta. Si no están en esa salida, dos de tus tres lectores no pueden verlos. - Que AI Overviews no te dé falsa tranquilidad. Google renderiza tu JavaScript, así que una visibilidad decente en AIO no demuestra nada sobre ChatGPT, Claude o Perplexity. Audítalos por separado.
- Trata tu árbol de accesibilidad como una API. Los agentes de OpenAI y Perplexity priorizan roles y etiquetas ARIA antes de recurrir a la visión. El HTML semántico y las etiquetas honestas ya no son solo una casilla de accesibilidad; son la forma en que las máquinas operan tu interfaz.
- Diseña para el extremo del 97 % de la curva. Las páginas densas, recargadas y de bajo contraste empujan al agente que lee con visión hacia la zona de degradación donde empieza a adivinar. La jerarquía clara y los tamaños de letra legibles ahora sirven a dos audiencias.
- Mantén los datos críticos sin ambigüedad. Un agente que malinterpreta un precio desde una captura falla exactamente como el test del hex: en silencio y con confianza.
Qué estamos construyendo encima de esto
pxpipe demostró el mecanismo sobre el tráfico de un desarrollador. La pregunta que nos interesa en 498A es qué hace a escala de auditoría, y se está convirtiendo en dos líneas de trabajo.
La primera va de economía de la simulación. Un estudio de marca de GEORadar lanza entre 3.000 y 30.000 prompts personalizados contra cinco LLMs más AI Overviews de Google. Cada una de esas llamadas carga un bloque de contexto estático: definiciones de personas, instrucciones de mercado, catálogos de producto, rúbricas de evaluación. Se repite miles de veces por estudio, es denso en tokens y nada de él necesita recall byte-exacto. Es exactamente el perfil que favorece la matemática de la compresión. Así que estamos probando la compresión óptica de ese bloque estático sobre nuestro propio motor de simulación. Las ratios públicas dicen que el contenido denso comprime alrededor de 3x; lo que estamos midiendo es qué compra eso de vuelta en un estudio completo: más prompts por presupuesto, más motores por prompt, o la misma auditoría a una fracción del coste. Hasta que estén nuestros números, se queda etiquetado como lo que es, un experimento.
La segunda línea apunta en la dirección contraria. Nuestras auditorías interrogan a los modelos sobre las marcas por el canal de texto, y el lado técnico ya comprueba qué pueden recoger los crawlers. Al tercer lector todavía no lo audita nadie. Estamos prototipando exactamente eso: darle páginas de marca a modelos de visión tal como las ven los navegadores agénticos, captura de pantalla más árbol de accesibilidad, y puntuar qué sobrevive al viaje. ¿Qué datos extrae de verdad un lector de visión? ¿A qué densidad de layout resbala la página hacia la zona de confabulación que midió DeepSeek? Para S.A.M., nuestra herramienta de alineamiento semántico, esto extiende la validación a un segundo canal: una claim ahora tiene que sobrevivir como texto para el crawler y como píxeles para el agente. El alineamiento semántico era una propiedad de tu copy. Está pasando a ser también una propiedad de tu layout.
Sobre el lado texto de esa maquinaria escribí en cómo buscan, recuperan y responden los LLMs con datos web en tiempo real. El lado visión es más nuevo, y la mayoría de webs no se han comprobado contra él ni una sola vez. Ese hueco es la oportunidad.
Texto que se difumina como la memoria
Volvamos a la idea de cierre de DeepSeek, porque lo reencuadra todo. Si el texto renderizado como imagen es barato y legible, entonces el contexto antiguo no tiene por qué resumirse ni borrarse. Puede guardarse como imágenes que pierden resolución con el tiempo. La conversación de ayer a alta resolución. La del mes pasado a la mitad. La del año pasado como una miniatura borrosa que todavía conserva la esencia.
Eso ya no es un truco de facturación. Es una arquitectura de memoria artificial que se comporta como la biológica, construida con el mismo mecanismo que convierte 42,21 dólares en 4,51. Y para quien lanza simulaciones a escala de auditoría, es también la diferencia entre muestrear un mercado y saturarlo.
El canal entre los modelos de lenguaje y el texto se vuelve cada vez más extraño. Pasamos años enseñando a las máquinas a leer. Ahora la forma más barata de entregarle texto a una máquina construida sobre el lenguaje es, cada vez más a menudo, enseñarle una imagen.
Fuentes técnicas consultadas
- teamchong: pxpipe, proxy local que renderiza el contexto de las peticiones como PNGs, tablas de benchmark y trazas de coste en producción (MIT).
- Wei et al., DeepSeek-AI: DeepSeek-OCR: Contexts Optical Compression, curvas de compresión-precisión, arquitectura DeepEncoder y la propuesta de memoria óptica (CC BY 4.0).
- Li et al.: Text or Pixels? It Takes Half, eficiencia de tokens de las entradas de texto visuales en LLMs multimodales (CC BY 4.0).
- Faysse et al.: ColPali: Efficient Document Retrieval with Vision Language Models, ICLR 2025, retrieval documental visual y el benchmark ViDoRe.
- Anthropic: Documentación de visión, patches de 28x28 píxeles, topes de resolución por tier y tablas de coste en tokens.
- Google AI for Developers: Understand and count tokens, tokenización de imágenes en Gemini por tiles de 768x768.
- OpenAI: Vision guide, precio de imagen base más por tile.
- Vercel: The rise of the AI crawler, mediciones en producción del comportamiento con JavaScript de GPTBot, ClaudeBot y PerplexityBot.
- Stan Ventures: Gemini AI renders JavaScript like Googlebot, la confirmación de Martin Splitt sobre la infraestructura de renderizado de Gemini.
- Sean Goedecke: Should LLMs just treat text content as an image?, expresividad de tokens discretos frente a continuos.
- Sinaptik AI: PixelPrompt, implementación open source alternativa de compresión de contexto texto-a-imagen.