A finals de desembre de 2025 em vaig topar, com mig GitHub, amb un petit projecte open source anomenat pxpipe, trending aquella setmana amb una afirmació que sona a error de facturació: la mateixa sessió de Claude Code que costava 42,21 dòlars com a text pla en va costar 4,51 quan les parts voluminoses de la petició es van convertir en imatges PNG abans de sortir de la màquina.
Mateix model, mateixa tasca, mateixes respostes. L'única diferència és que el model va llegir la major part del seu context amb els ulls en lloc de fer-ho amb el tokenitzador.
L'A/B que va córrer pertot arreu: la mateixa sessió, 42,21 dòlars com a text i 4,51 amb el context imaginat. Font: repo de pxpipe (MIT).
Val la pena desmuntar aquest número, perquè el mecanisme que hi ha al darrere és més gran que una eina. Explica una palanca de cost real per a qualsevol que operi agents o pipelines de context llarg. I connecta amb una segona pregunta que gairebé ningú no ha lligat encara a la primera: quan un sistema d'IA visita el teu web en temps real, què veu exactament? La resposta, cada cop més, passa pel mateix canal de visió.
El mecanisme: les imatges es cobren per píxels, no per caràcters
Tots els models multimodals posen preu a una imatge segons les seves dimensions. Una imatge de 1000x1000 píxels costa els mateixos tokens tant si conté un buit blanc com 5.000 paraules de documentació densa. El comptador de tokens compta píxels. Tant li fa què hi hagi pintat a sobre.
El text, en canvi, es cobra caràcter a caràcter. En trànsit real de Claude Code, el contingut dens tipus codi, JSON i logs surt a aproximadament un caràcter per token de text. Aquest mateix contingut renderitzat en una imatge ben compactada surt a uns 3,1 caràcters per token d'imatge.
Aquest forat és tot el truc. L'exemple canònic de la documentació de pxpipe: un bloc d'uns 48.000 caràcters (system prompt més documentació d'eines) costa uns 25.000 tokens com a text. Renderitzat com un PNG dens, costa uns 2.700 tokens d'imatge. La mateixa informació, un 89 % menys de tokens en aquell bloc.

El que rep el model: 48.000 caràcters amb l'espai en blanc minificat, recol·locats en files completes, amb marques ↵ on hi havia els salts de línia originals. Font: repo de pxpipe (MIT).
Perquè un codificador visual pugui llegir aquesta pàgina, el text passa per tres preparacions. S'elimina l'espai en blanc redundant. Les línies es redistribueixen fins a omplir files completes de la imatge, amb columnes que s'ajusten a uns 1.928 píxels d'amplada. I s'insereixen petites marques ↵ on hi havia els salts de línia originals, perquè l'estructura sobrevisqui a la compactació. Una pàgina densa empaqueta uns 92.000 caràcters.
Per què els píxels guanyen les paraules portant paraules
El que és contraintuïtiu no és la facturació. És que el model realment pot llegir això.
Sean Goedecke va escriure una bona anàlisi de per què els comptes surten. Un token de text és una elecció discreta: una opció entre un vocabulari d'unes 50.000 entrades, que després es mapa a un vector d'embedding. Un token d'imatge no té aquesta restricció. Pot ocupar qualsevol punt de l'espai d'embeddings, i això el fa molt més expressiu per unitat. La recerca de DeepSeek hi posa número: d'un sol token d'imatge se'n poden recuperar uns 10 tokens de text amb precisió gairebé perfecta.
La idea no és nova, i això és part del que fa interessant el moment. La vaig veure en un post, la vaig provar i l'he continuat fent servir des de llavors. La gent fa anys que enganxa captures en models multimodals, i l'objecció de sempre era la mateixa: els codificadors visuals no eren prou fiables llegint lletra petita i densa, així que ningú amb seny no encaminava context de producció per aquí. El que va canviar entre 2024 i ara són els codificadors. Quan DeepSeek va publicar els seus resultats de compressió òptica i pxpipe va publicar els seus evals, la conversa va passar de "això ni tan sols funcionaria" a "aquesta és la ràtio exacta on deixa de funcionar". Aquesta és la diferència entre un truc de festa i una opció d'enginyeria.
Així compten avui els tokens d'imatge els principals proveïdors:
| Proveïdor | Com es cobra una imatge | Una imatge de 1000x1000 px |
|---|---|---|
| Anthropic (Claude) | Patches de 28x28 píxels, un token visual cadascun: ⌈amplada/28⌉ x ⌈alçada/28⌉ | 1.296 tokens |
| OpenAI (detail high) | 85 tokens base + 170 per tile de 512x512 després del reescalat | 765 tokens |
| Google (Gemini) | 258 tokens fixos si ≤384 px, si no 258 per tile de 768x768 | 1.032 tokens |
En els models actuals de Claude (Fable 5, Opus 4.7 i 4.8), una imatge té un sostre de 4.784 tokens visuals amb una vora llarga de fins a 2.576 píxels. L'amplada de render de pxpipe, 1.928 píxels, hi cap amb marge. Res d'això no és casualitat.
La lletra petita de cada proveïdor
Els detalls importen més que la fórmula de titular, perquè cada proveïdor hi amaga compromisos diferents.
Els models antics d'Anthropic limitaven les imatges a 1.568 píxels de vora llarga i 1.568 tokens visuals. Tot el que arribés més gran es reduïa abans de processar-se, cosa que posava un sostre silenciós al cost i a la resolució alhora. Encara trobaràs en textos antics l'aproximació "tokens igual a amplada per alçada entre 750". La matemàtica de patches la va substituir: 28 per 28 píxels per token visual, arrodonint cap amunt a cada eix. Per a una imatge de 1000x1000 les dues fórmules cauen a menys del 3 % l'una de l'altra, i per això la regla vella va sobreviure tant de temps.
OpenAI treballa en dos passos: la imatge s'escala per cabre dins d'un quadrat de 2048 píxels, després el seu costat més curt es porta a 768 píxels, i només llavors s'aplica el trossejat en tiles de 512. El mode "low detail" s'ho salta tot per 85 tokens fixos, que per llegir text no serveix de res però per a "això és un gat" va sobrat.
L'enfocament de Google és el més directe: qualsevol cosa de fins a 384 píxels per ambdós costats són 258 tokens, punt. A partir d'aquí, tiles de 768 píxels a 258 cadascun.
D'aquí en surten tres conseqüències. Primera: la mida òptima de render depèn del proveïdor, així que un pipeline afinat per a Claude malbarata diners a Gemini. Segona: redimensionar abans de pujar és una decisió teva, i prendre-la conscientment guanya a deixar que l'API redueixi per tu. Tercera: els sostres per imatge fan que els documents molt llargs prefereixin diverses pàgines de densitat mitjana abans que una de sola gegant. pxpipe empaqueta uns 92.000 caràcters per pàgina i simplement emet un array de PNGs quan el contingut desborda.
![]()
La idea en una imatge: context idèntic, 90 tokens com a text, 50 com a imatge. Font: "Text or Pixels? It Takes Half" (arXiv 2510.18279), CC BY 4.0.
Què diu la recerca
Dos papers de l'octubre de 2025 van posar això sobre base sòlida.
"Text or Pixels? It Takes Half" va provar la idea de manera sistemàtica en GPT-4.1-mini i Qwen2.5-VL-72B. El muntatge era acurat: text compost amb LaTeX a 300 DPI, mida de lletra adaptativa buscant un fill ratio de 0,8, resolucions de 600x800 a 750x1000 píxels. Renderitzar text llarg com a imatge va aconseguir una compressió d'aproximadament 2:1 (entre un 38 % i un 58 % menys tokens de decoder) mantenint la precisió a menys de 3 punts del baseline només-text. En retrieval tipus agulla al paller, el braç imaginat va puntuar entre el 97 % i el 99 %; en resum sobre CNN/DailyMail va batre baselines de compressió dedicats com LLMLingua-2 a ràtios equivalents. I hi va haver un extra que ningú no esperava: en Qwen2.5-VL-72B, la seqüència de decoder més curta va fer la inferència entre un 25 % i un 45 % més ràpida de punta a punta. Més barat i més ràpid, amb el mateix truc.
DeepSeek-OCR, publicat el mateix mes, va anar més enllà i va cartografiar els límits. El seu treball de "compressió òptica de contextos" mostra que mentre la ràtio entre tokens de text i tokens de visió es manté per sota de 10x, la precisió de descodificació aguanta al 97 %. Força fins a 20x i la precisió cau al voltant del 60 %. La corba entre aquests dos punts és la llista de preus de tota aquesta tècnica.
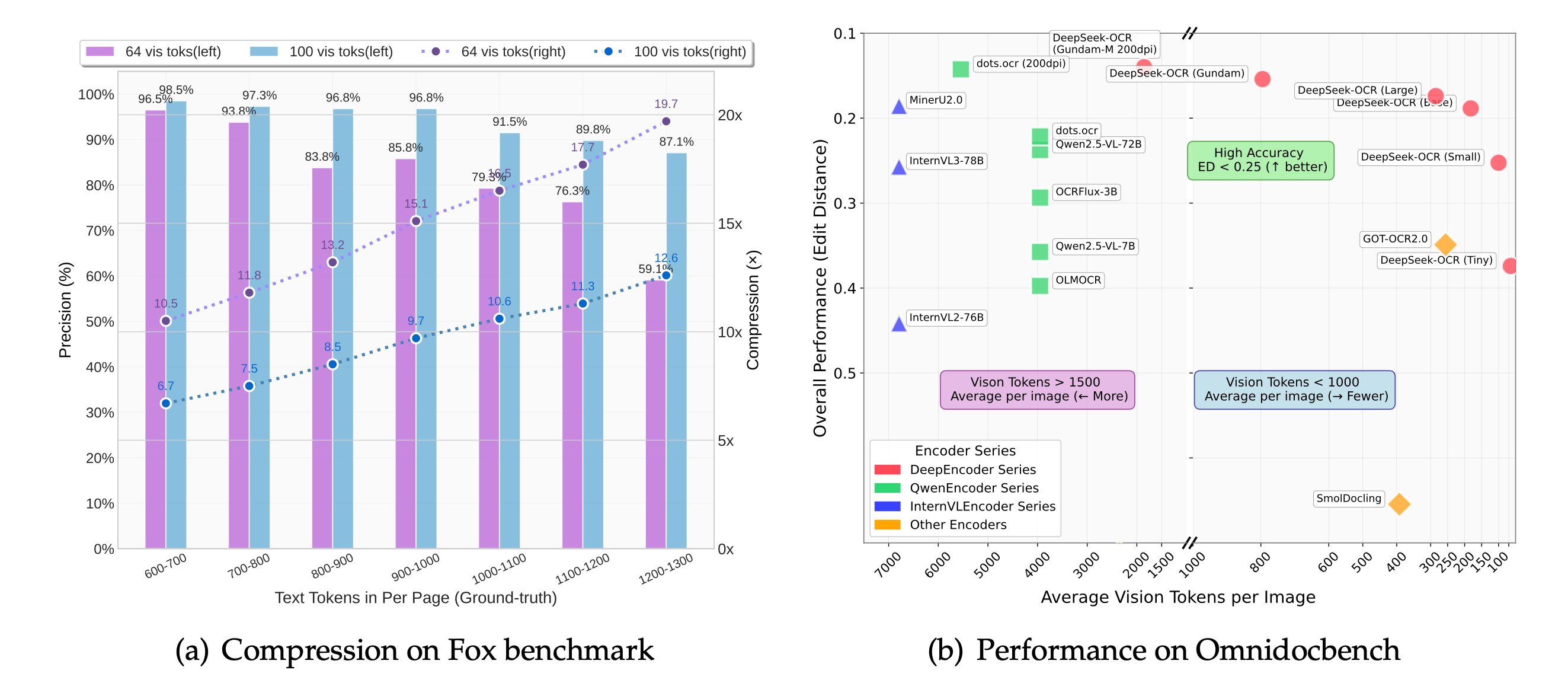
La frontera de la tècnica: la precisió aguanta prop del 97 % per sota de compressió 10x, i després es degrada. A OmniDocBench, 100 tokens de visió per pàgina baten sistemes que en gasten 256, i menys de 800 baten sistemes que en gasten més de 6.000. Font: DeepSeek-OCR (arXiv 2510.18234), CC BY 4.0.
Els números d'eficiència costen d'ignorar. DeepSeek-OCR llegeix una pàgina de document amb 100 tokens de visió i bat GOT-OCR2.0, que en gasta 256 per pàgina. Amb menys de 800 supera MinerU2.0, que en fa una mitjana de més de 6.000. En producció, DeepSeek fa servir això per generar dades d'entrenament per a LLMs a més de 200.000 pàgines al dia en una sola A100-40G.
La secció de discussió del paper conté la idea més de ciència-ficció de tot aquest espai: la memòria òptica. Desar l'historial antic d'una conversa com a imatges a resolució cada cop menor, de manera que el context llunyà literalment es difumina com es difuminen els records humans. Hi tornem al final.
Dins d'un pipeline de producció
pxpipe és la implementació més instructiva de llegir perquè publica els seus evals i els seus casos de fallada. Funciona com un proxy local entre el teu client i l'API de Claude. Les peticions passen byte a byte idèntiques excepte tres categories de contingut, cadascuna darrere d'una porta de rendibilitat: resultats d'eines per sobre d'uns 6.000 caràcters de contingut dens, torns antics de conversa per darrere de la cua viva, i el bloc estàtic de system prompt més documentació d'eines.
Dues regles de disseny importen més que la resta. Els torns recents sempre es queden com a text. I el prefix estàtic es conserva intacte, perquè trencar el prompt caching es menjaria l'estalvi.
Els resultats mesurats, de les mateixes taules de benchmark del projecte:
| Test | Baseline text | Amb context imaginat |
|---|---|---|
| Aritmètica nova, Claude Fable 5 (n=100) | 100/100 | 100/100, amb un 38 % menys tokens |
| Gist recall A/B (n=98) | 98/98 | 98/98 |
| State tracking (n=18) | 18/18 | 18/18 |
| SWE-bench Lite (n=10) | 10/10 | 10/10, peticions un 65 % més petites |
| Recall d'hex de 12 caràcters, Opus (n=15) | 15/15 | 0/15 |
Mira un altre cop aquesta última fila. Hi tornem de seguida.
A SWE-bench Pro, el benchmark agèntic difícil, el braç imaginat va resoldre 14 de 19 tasques contra 15 de 19 del text pla, amb peticions un 60 % més petites i 18 de 19 execucions coincidint en el veredicte final. Aquesta és la forma honesta del compromís en feina difícil: un petit impost de precisió en els problemes més durs, comprat a més de la meitat de preu.
De punta a punta, sobre un snapshot de 13.709 peticions reals, la factura va baixar un 59 %, de 100 dòlars a uns 41. Les traces on la compressió aplicava amb força van sortir entre un 70 % i un 74 % més barates.
Hi vénen dos costos operatius amb el paquet. Codificar PNGs afegeix latència en peticions grans, i es nota quan el teu pipeline és sensible a la latència i no al cost. I la tècnica està batallada en contingut ASCII i Latin-1; el CJK funciona però el projecte el tracta de manera conservadora, amb un empaquetat menys agressiu. Si el teu context és majoritàriament xinès o japonès, la teva ràtio de compressió serà pitjor que els números de titular.
Quan imaginar el teu context suma, i quan resta
Qualsevol article sobre aquesta tècnica que només citi l'estalvi t'està fent un mal favor. El mètode és amb pèrdua, i falla d'una manera concreta i lletja.
El primer que es trenca és el recall exacte de cadenes curtes. En el test de pxpipe, Opus va recordar cadenes hex de 12 caràcters des de contingut imaginat 0 vegades de 15. El més recent Fable 5 va arribar a 13 de 15. I les fallades no són errors que puguis caçar: el model confabula un valor plausible amb tota la confiança en lloc de dir que no ho pot llegir. El projecte documenta un cas real d'un nom recordat malament, amb seguretat absoluta, des d'historial imaginat.
També depèn del model. La tècnica funciona perquè els codificadors visuals frontera actuals (Claude Fable 5, GPT 5.6) llegeixen text dens gairebé perfecte. Opus 4.7 i 4.8 el malinterpreten al voltant d'un 7 % de les vegades, i per això pxpipe els deixa en opt-in. Un model sense un bon codificador lector converteix el teu context comprimit en soroll.
La regla pràctica honesta: imaginar suma quan el contingut és context a granel per raonar (codi, documentació, logs, torns antics de conversa). Resta quan qualsevol byte importa exactament. Hashes, claus d'API, IDs, telèfons i tot el que hagis de citar de tornada literal ha de quedar-se com a text, sempre.
Un avís més, i és l'estratègic: l'arbitratge es mou. Quan Anthropic va publicar Opus 4.7, la resolució nativa màxima d'imatge va saltar de 1.568 a 2.576 píxels de vora llarga, i les captures típiques van passar d'uns 1.558 tokens a 4.739. La mateixa imatge, el triple de cost, en una release. La lliçó no és "fes servir el truc". La lliçó és: entén l'economia per píxel del teu proveïdor i mesura-la, perquè canvia sense preguntar-te.
Prova-ho en deu minuts
Si fas servir Claude Code, l'experiment costa dues ordres:
npx pxpipe-proxy
ANTHROPIC_BASE_URL=http://127.0.0.1:47821 claudeUn dashboard a 127.0.0.1:47821 ensenya cada conversió i els tokens estalviats. El proxy només toca models de la seva allowlist; tota la resta passa byte a byte idèntica, i pots apagar-lo del tot amb PXPIPE_MODELS=off.
Per als teus propis pipelines, la mateixa maquinària està disponible com a llibreria:
import { renderTextToPngs, transformAnthropicMessages } from "pxpipe";
const imgs = await renderTextToPngs(bigToolResultText);
const { body, applied } = await transformAnthropicMessages({
body: requestBytes,
model: "claude-fable-5",
});Abans de fiar-te de cap número, mesura el teu propi baseline. L'endpoint count_tokens d'Anthropic és gratuït, i comparar peticions imaginades contra planes sobre el teu trànsit real et porta una tarda. La meva checklist per a qui adopti això:
- Filtra per densitat. La prosa comprimeix malament; el codi, el JSON i els logs comprimeixen bé.
- Mantén la cua viva de la conversa com a text, sempre.
- Deixa fora del camí imaginat tot el que sigui byte-exacte (hashes, claus, IDs, imports).
- Torna a mesurar amb cada release de model. El repricing d'Opus 4.7 va triplicar el cost de les imatges d'un dia per l'altre.
- Registra què s'ha comprimit. Quan aparegui una confabulació, voldràs saber què estava llegint el model.
La part que gairebé ningú no connecta: així llegeixen també el teu web les IAs
Tot l'anterior tracta el text-com-imatge com un truc de cost que apliques a les teves pròpies peticions. Ara gira la direcció. Quan ChatGPT, Claude, Perplexity o un navegador agèntic visiten una pàgina del teu web en temps real, què veuen?
Resulta que el teu web no té un lector d'IA. En té tres, i no es posen d'acord.
El teu web ja té tres lectors d'IA: el crawler, Google i l'agent. I cap d'ells no veu la mateixa pàgina.

La mateixa pàgina, tres lectures: HTML cru per als crawlers, pàgina renderitzada per a Google, píxels per als agents.
Lector u: els crawlers. Cada empresa d'IA llança tres famílies de bots contra el teu web. Un crawler d'entrenament (GPTBot, ClaudeBot) recull contingut per a models futurs. Un bot d'índex de cerca (OAI-SearchBot, Claude-SearchBot) alimenta la capa de cerca de l'assistent. I un fetcher disparat per l'usuari (ChatGPT-User, Perplexity-User) colpeja la teva pàgina en viu, en els segons entre la pregunta d'un usuari i la resposta. Aquest últim és el "temps real" de les respostes d'IA en temps real.
A mitjan 2026, cap d'ells no executa JavaScript. Cap, en cap de les tres famílies. L'anàlisi de trànsit de producció de Vercel va trobar que GPTBot descarrega fitxers JavaScript al voltant de l'11,5 % de les vegades (ClaudeBot el 23,8 %) i mai no els executa. Recullen l'HTML cru, n'extreuen el que hi ha i continuen. Sense segona passada, sense cua de renderitzat. Si el teu contingut només existeix al DOM després del renderitzat en client, per a aquests sistemes no existeix.
Lector dos: Google, l'excepció. Gemini i AI Overviews hereten la infraestructura de Googlebot, i Googlebot sí que renderitza JavaScript. Martin Splitt, de Google, ho ha confirmat. La conseqüència pràctica és estranya i molt real: la mateixa pàgina pot ser completament visible per a les superfícies d'IA de Google i invisible per a ChatGPT, Claude i Perplexity alhora. Si la teva marca apareix a AI Overviews però mai a les respostes de ChatGPT, revisa quant del teu contingut depèn de JavaScript abans de culpar el model.
Lector tres: els agents. Els navegadors agèntics com Atlas d'OpenAI (mogut pel seu Computer-Using Agent) i Comet de Perplexity llegeixen la pàgina completament renderitzada, amb una barreja de snapshots de l'arbre d'accessibilitat, parsing del DOM i captures enviades a un model de visió. Aquí és on la primera meitat d'aquest article torna a aparèixer: els agents estan llegint pàgines web pel mateix canal de visió, amb la mateixa economia i la mateixa corba de degradació. Els números de DeepSeek apliquen també aquí. Una pàgina neta i ben estructurada es llegeix al 97 %. Una de densa i desordenada rellisca cap a l'extrem del 60 %, i l'agent omple els buits amb suposicions segures de si mateixes.
Hi ha un quart patró que convé conèixer al costat del retrieval. ColPali (ICLR 2025) va demostrar que per a cerca documental, saltar-se l'OCR del tot i fer embedding directe de les imatges de pàgina bat el pipeline clàssic d'extreure i trossejar: 0,81 contra 0,66 de NDCG@5, indexant pàgines en 0,39 segons en lloc de 7,22. El layout, les taules i les figures que l'extracció de text destrueix resulten portar significat recuperable. L'estructura visual és informació.
Què significa això si publiques contingut
Si tens un web que t'agradaria que els sistemes d'IA llegissin bé, la divisió en tres lectors es tradueix en feina comprovable:
- Serveix la substància en HTML cru. Renderitza en servidor o prerenderitza tot el que vulguis que vegin crawlers i fetchers en viu: preus, especificacions, FAQs, comparatives. El test costa una ordre: fes
curla la teva pàgina i busca les teves dades clau a la resposta. Si no hi són, dos dels teus tres lectors no les poden veure. - Que AI Overviews no et doni falsa tranquil·litat. Google renderitza el teu JavaScript, així que una visibilitat decent a AIO no demostra res sobre ChatGPT, Claude o Perplexity. Audita'ls per separat.
- Tracta el teu arbre d'accessibilitat com una API. Els agents d'OpenAI i Perplexity prioritzen rols i etiquetes ARIA abans de recórrer a la visió. L'HTML semàntic i les etiquetes honestes ja no són només una casella d'accessibilitat; són la manera com les màquines operen la teva interfície.
- Dissenya per a l'extrem del 97 % de la corba. Les pàgines denses, recarregades i de baix contrast empenyen l'agent que llegeix amb visió cap a la zona de degradació on comença a endevinar. La jerarquia clara i les mides de lletra llegibles ara serveixen dues audiències.
- Mantén les dades crítiques sense ambigüitat. Un agent que malinterpreta un preu des d'una captura falla exactament com el test de l'hex: en silenci i amb confiança.
Què estem construint a sobre d'això
pxpipe va demostrar el mecanisme sobre el trànsit d'un desenvolupador. La pregunta que ens interessa a 498A és què fa a escala d'auditoria, i s'està convertint en dues línies de treball.
La primera va d'economia de la simulació. Un estudi de marca de GEORadar llança entre 3.000 i 30.000 prompts personalitzats contra cinc LLMs més AI Overviews de Google. Cadascuna d'aquestes crides carrega un bloc de context estàtic: definicions de persones, instruccions de mercat, catàlegs de producte, rúbriques d'avaluació. Es repeteix milers de vegades per estudi, és dens en tokens i res d'ell no necessita recall byte-exacte. És exactament el perfil que afavoreix la matemàtica de la compressió. Així que estem provant la compressió òptica d'aquest bloc estàtic sobre el nostre propi motor de simulació. Les ràtios públiques diuen que el contingut dens comprimeix al voltant de 3x; el que estem mesurant és què compra això de tornada en un estudi complet: més prompts per pressupost, més motors per prompt, o la mateixa auditoria a una fracció del cost. Fins que no hi hagi els nostres números, es queda etiquetat com el que és, un experiment.
La segona línia apunta en la direcció contrària. Les nostres auditories interroguen els models sobre les marques pel canal de text, i el costat tècnic ja comprova què poden recollir els crawlers. El tercer lector encara no l'audita ningú. Estem prototipant exactament això: donar pàgines de marca a models de visió tal com les veuen els navegadors agèntics, captura de pantalla més arbre d'accessibilitat, i puntuar què sobreviu al viatge. Quines dades extreu de debò un lector de visió? A quina densitat de layout rellisca la pàgina cap a la zona de confabulació que va mesurar DeepSeek? Per a S.A.M., la nostra eina d'alineament semàntic, això estén la validació a un segon canal: una claim ara ha de sobreviure com a text per al crawler i com a píxels per a l'agent. L'alineament semàntic era una propietat del teu copy. Està passant a ser també una propietat del teu layout.
Sobre el costat text d'aquesta maquinària vaig escriure a com busquen, recuperen i responen els LLMs amb dades web actualitzades. El costat visió és més nou, i la majoria de webs no s'han comprovat contra ell ni una sola vegada. Aquest buit és l'oportunitat.
Text que es difumina com la memòria
Tornem a la idea de tancament de DeepSeek, perquè ho reenquadra tot. Si el text renderitzat com a imatge és barat i llegible, llavors el context antic no cal resumir-lo ni esborrar-lo. Es pot desar com a imatges que perden resolució amb el temps. La conversa d'ahir a alta resolució. La del mes passat a la meitat. La de l'any passat com una miniatura borrosa que encara conserva l'essència.
Això ja no és un truc de facturació. És una arquitectura de memòria artificial que es comporta com la biològica, construïda amb el mateix mecanisme que converteix 42,21 dòlars en 4,51. I per a qui llança simulacions a escala d'auditoria, és també la diferència entre mostrejar un mercat i saturar-lo.
El canal entre els models de llenguatge i el text es torna cada cop més estrany. Vam passar anys ensenyant les màquines a llegir. Ara la manera més barata de lliurar text a una màquina construïda sobre el llenguatge és, cada cop més sovint, ensenyar-li una imatge.
Fonts tècniques consultades
- teamchong: pxpipe, proxy local que renderitza el context de les peticions com a PNGs, taules de benchmark i traces de cost en producció (MIT).
- Wei et al., DeepSeek-AI: DeepSeek-OCR: Contexts Optical Compression, corbes de compressió-precisió, arquitectura DeepEncoder i la proposta de memòria òptica (CC BY 4.0).
- Li et al.: Text or Pixels? It Takes Half, eficiència de tokens de les entrades de text visuals en LLMs multimodals (CC BY 4.0).
- Faysse et al.: ColPali: Efficient Document Retrieval with Vision Language Models, ICLR 2025, retrieval documental visual i el benchmark ViDoRe.
- Anthropic: Documentació de visió, patches de 28x28 píxels, sostres de resolució per tier i taules de cost en tokens.
- Google AI for Developers: Understand and count tokens, tokenització d'imatges a Gemini per tiles de 768x768.
- OpenAI: Vision guide, preu d'imatge base més per tile.
- Vercel: The rise of the AI crawler, mesuraments en producció del comportament amb JavaScript de GPTBot, ClaudeBot i PerplexityBot.
- Stan Ventures: Gemini AI renders JavaScript like Googlebot, la confirmació de Martin Splitt sobre la infraestructura de renderitzat de Gemini.
- Sean Goedecke: Should LLMs just treat text content as an image?, expressivitat de tokens discrets davant de continus.
- Sinaptik AI: PixelPrompt, implementació open source alternativa de compressió de context text-a-imatge.